

Supervisez votre serveur rapidement avec Grafana Cloud
Sommaire
I. Présentation
Dans le monde de la supervision, il y a de nombreuse solutions disponible en Open Source : Nagios, Icinga, Centreon, EON, et j'en passe.
Mais il y a aussi des solutions plus généralistes, adaptables à ce type d'usage, c'est le cas de Grafana, une solution de visualisation de métriques quelles qu'elles soient et justement, s'en servir pour faire du monitoring permet la construction de tableaux de bord très complets et visuels.
Oui mais voilà, mettre en place une pile Prometheus, Grafana et configurer le tout n'est pas donné à tout le monde... Mais c'est pas grave, car Grafana a eu la très bonne idée de décliner son offre en version Cloud, et en plus, il y a une offre gratuite!
Je vais vous détailler dans ce tuto comment mettre en place un monitoring d'un serveur Linux ou Windows rapidement grâce à cette solution.
II. Pourquoi et comment ?
Grafana Cloud se présente comme "une plateforme d'observabilité en tant que service", en proposant un moteur de visualisation en mode cloud, donc hautement disponible et prêt à l'emploi.
Sur ce moteur peut venir se greffer plusieurs métriques, comme des serveurs Linux, des machines virtuelles Java, des processus Go, etc. Et seulement en quelques clics.
L'offre est déclinée en plusieurs versions, une gratuite et d'autres payantes, le résumé des offres est disponible ici.
L'offre gratuite permet la création de 10 tableaux de bord grâce à un maximum de 10 000 métriques avec une limite de 50 Go de données et 14 jours de rétention. C'est suffisant pour monitorer son serveur ou pour tester la solution. bien entendu, pour une utilisation plus poussée en entreprise, la solution gratuite ne suffira pas...
III. Mise en place
Tout d'abord, il faut créer un compte à l'adresse grafana.com et définir une URL personnelle pour vous et votre équipe (l'offre gratuite permet 3 utilisateurs).
Bien que le choix de la région d'hébergement soit présente, seule la région US est disponible, donc à prendre en considération tout de même en fonction du type de métrique qui y sera envoyée.
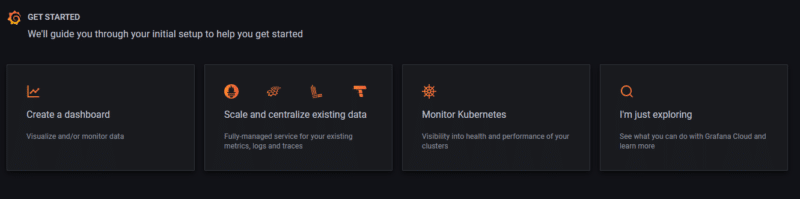
Une fois votre tenant disponible, vous pourrez spécifier ce que vous compter y faire :
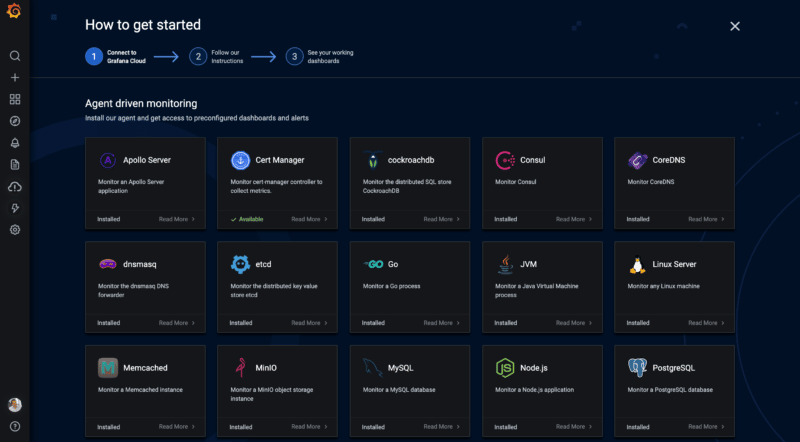
Pour notre usage, nous allons choisir "Create a Dashboard" pour y insérer par la suite notre serveur. Une proposition de tableaux de bord pré-configurés va alors vous être proposé, comme vous pouvez le voir, il y en a déjà beaucoup !
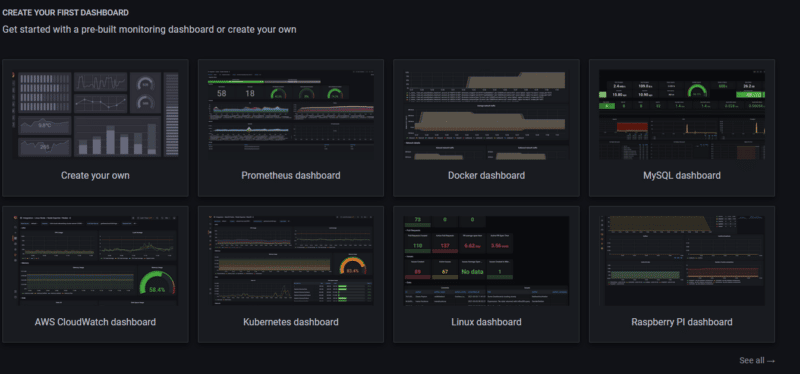
Nous allons choisir "See all" en bas à droite, ce qui vous amènera sur la page des intégrations où nous pourrons choisir le type de service à monitorer. Profitez-en pour parcourir toutes les possibilités!
A. Monitorer un serveur Linux
Pour cela, sur la page des intégrations (qui sera toujours disponible si vous souhaitez en rajouter, il suffit de cliquer sur "Linux Server" :
Sur la page de configuration, il faudra alors choisir le type de distribution, l'architecture et donner un nom à votre serveur :
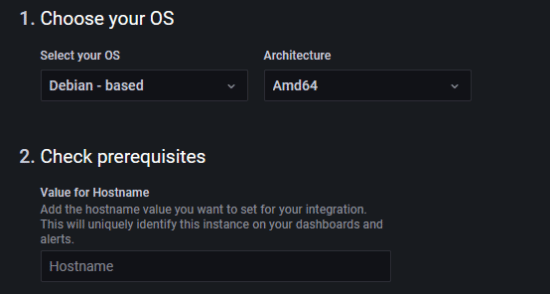
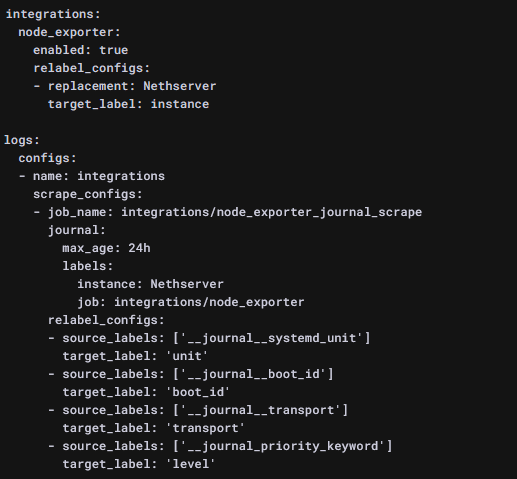
L'intégration des métriques de votre serveur passe par l'installation d'un agent, dont le code source est disponible sur GitHub, basé sur Prometheus, la configuration future de l'agent est affichée à l'écran, de sorte que vous saurez ce qui sera monitoré. Par exemple dans mon cas, les logs seront collectés via systemd :
Si ce type de monitoring ne vous conviens pas, Grafana nous propose aussi une configuration basée sur la collecte des logs contenus dans /var/log :
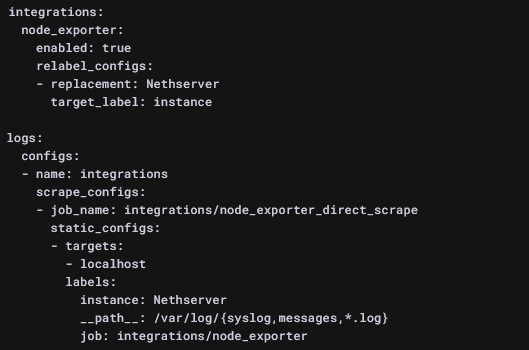
Dans les deux cas, il suffit de cliquer sur le bouton "Install integration" pour voir apparaître le code à copier et coller dans votre terminal. Oui oui, c'est tout!
sudo ARCH=amd64 GCLOUD_STACK_ID="473122" GCLOUD_API_KEY="masqué" GCLOUD_API_URL="https://integrations-api-us-central.grafana.net" /bin/sh
-c "$(curl -fsSL https://raw.githubusercontent.com/grafana/agent/release/production/grafanacloud-install.sh)"
Si on décompose, le script va définir 4 variables :
- ARCH: Architecture de votre serveur
- GCLOUD_STACK_ID : l'identifiant de votre tenant Grafana Cloud
- GCOUD_API_KEY : la clé API de votre tenant, celle-ci est personnelle, c'est pourquoi elle est masqué dans l'exemple ci-dessus.
- GCLOUD_API_URL : le chemin permettant l'upload des métriques
Viens ensuite l'installation de l'agent à proprement parlé depuis les dépots GitHub.
Une fois l'installation completée, nous pouvons vérifier que l'agent fonctionne bien avec la commande :
sudo systemctl status grafana-agent.service
Ce qui dons mon cas ne se termine pas bien...

Si j'exécute la commande journalctl -xe, je vois tout de suite où est le problème :
msg="error creating the agent server entrypoint" err="creating HTTP listener: listen tcp 127.0.0.1:9090: bind: address already in use"
Et oui, l'agent utilise le port 9090 et manque de bol, ce port est déjà utilisé sur ma machine. Il faut donc modifier la configuration de l'agent qui est située à "/etc/grafana-agent.yaml".
nano /etc/grafana-agent.yaml
Dans ce fichier de configuration vous retrouverez les clés API et URL définies précédemment, il ne faut surtout pas y toucher, sans quoi la remontée des logs ne se fera pas! Autre chose importante à savoir si vous n'êtes pas habitué à YAML, ce langage est très tatillon sur l'indentation, c'est même la marque de fabrique de celui-ci et ce qui lui permet de définir les clés et valeurs (YAML = Yep Another Markup Language) donc toute modification devra suivre les mêmes règles.
Pas de chance pour moi, le numéro de port n'est pas mentionné ici. Pour cela, il va falloir modifier un autre fichier de configuration qui se trouve lui dans "/etc/sysconfig/grafana-agent". Là, je trouve mon bonheur:
CUSTOM_ARGS="-server.http.address=127.0.0.1:9090 -server.grpc.address=127.0.0.1:9091"
Je peux donc ici changer le port pour un autre non utilisé et redémarrer le service :
sudo systemctl restart grafana-agent.service
Et je revérifie le bon fonctionnement :

Ouf! De retour sur Grafana Cloud, je peux cliquer sur le bouton "Test Integration" pour vérifier que mon tenant reçoit bien les métriques , ce qui est mon cas. En cliquant sur "View Dashboard", une page me propose des dashboards pré-configurés, en fonction des métriques reçues. Si je clique sur le premier de la liste, je peux donc profiter des information collectées, compilées et retranscrites sur un magnifique tableau de bord :
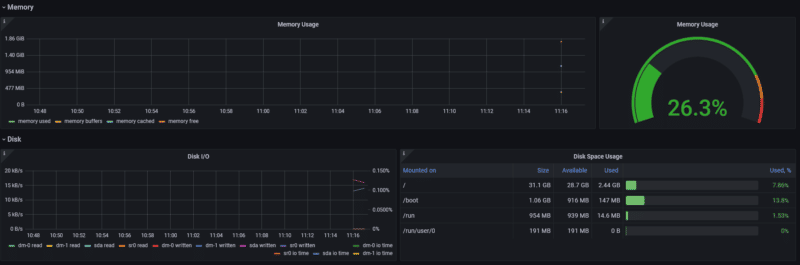
Note : Soyez patients! Le tableau de bord peut s'avérer vide, le temps que toutes les métriques soient collectées.
B. Monitorer un serveur Windows
Pour les serveur Windows, le cheminement est quasiment le même.
Si vous avez déjà mis un serveur ou un service autre, retournez dans le menu "Integrations" (l’icône en forme d'éclair à gauche), ici il est possible de choisir "Windows" :
Là encore, on nous propose un script prêt à l'emploi en Powershell pour l'installation :
curl -L https://raw.githubusercontent.com/grafana/agent/release/production/grafanacloud-install.ps1 --output grafanacloud-install.ps1
Note : La syntaxe proposée par Grafana Cloud est quelque peut... exotique pour PowerShell. Si vous voulez que cela fonctionne, préférez :
wget https://raw.githubusercontent.com/grafana/agent/release/production/grafanacloud-install.ps1 -outfile grafanacloud-install.ps1
Puis un script pour la configuration de celui-ci :
powershell -executionpolicy Bypass -File ".\grafanacloud-install.ps1" -GCLOUD_STACK_ID "473122"
-GCLOUD_API_KEY "masqué" -GCLOUD_API_URL "https://integrations-api-us-central.grafana.net"
Vous remarquerez qu'il s'agit des mêmes variables que pour le script Linux.
Si vous ne souhaitez pas utiliser Powershell, l'exécutable de l'agent est également disponible sur cette même page
Note : Windows Smart Screen risque de vous alerter sur l'installateur, pas de panique, vous pouvez l'exécuter.
Si vous optez pour cette dernière solution, il faudra changer la configuration à la main, elle se trouve dans "C:\Program Files\Grafana Agent\agent-config.yaml"
Vous pouvez vous aider du modèle disponible ici pour adapter à votre environnement.
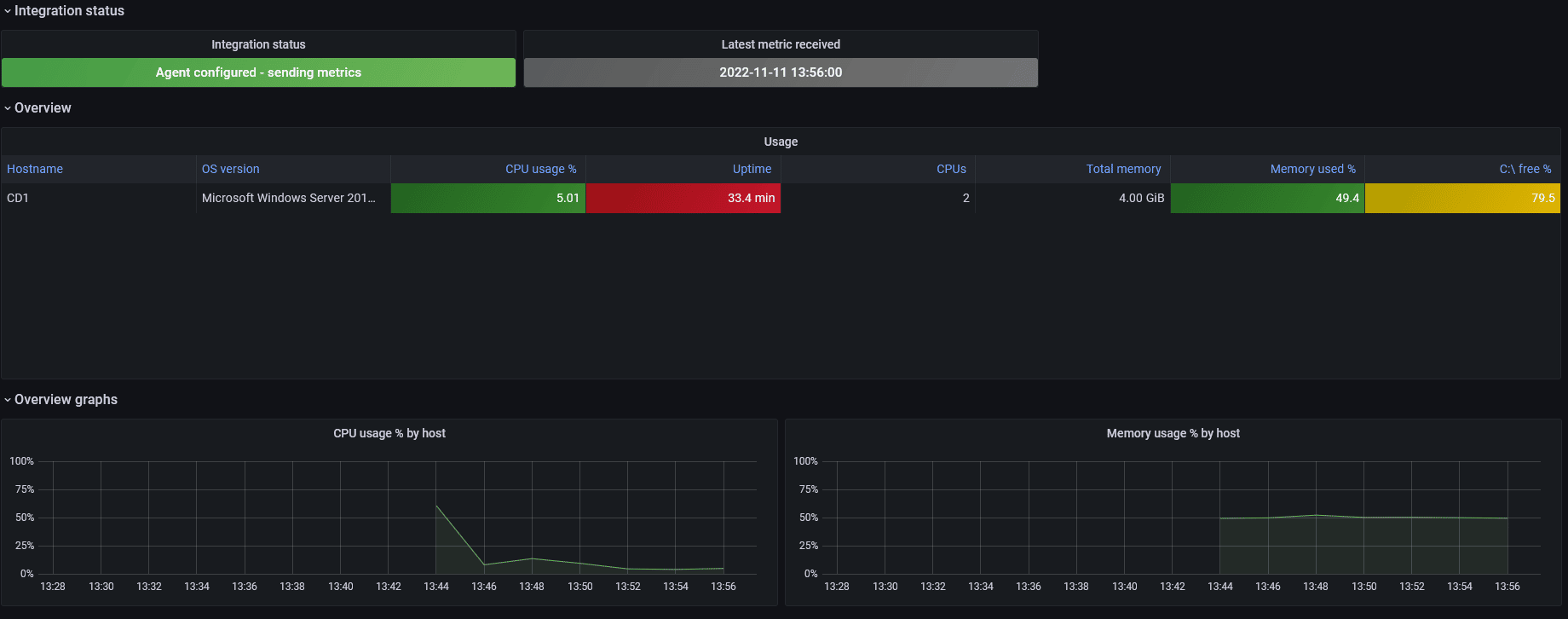
Une fois l'agent configurer, un petit clic sur "Test integration" pour vérifier que tout est en ordre, puis si tout est OK, un clic sur "View Dashboard". Le premier nous fait un récapitulatif des logs reçus, le deuxième (Windows overview) nous fournit les infos de monitoring classiques :
IV. Créer des alertes
Monitorer c'est bien mais on ne peut pas toujours avoir les yeux sur notre tableau de bord. Heureusement, Grafana permet la création d'alertes personnalisées à partir des information reçues des agents. A titre personnel, je trouve cette création peu intuitive, je vais donc tâcher de vous la décortiquer avec un exemple afin que vous puissiez créer les vôtres.
A. Fonctionnement de Grafana
Grafana à un mode de fonctionnement similaire à une base de données. Il possède une ou plusieurs source de données, (Prometheus, InfluxDB, etc.) sur lesquelles il fait des requêtes pour obtenir des informations qu'il transforme ensuite pour les préparer à la visualisation.
Comme il y a plusieurs sources de données possibles, il y a plusieurs méthodes de requêtes possibles, et au sein même d'une source de donnée, il faut connaître sa structure pour pouvoir créer des requêtes pertinentes. Il faut également connaître les méthodes et moyens de transformation des données pour créer des données "lisibles".
Prenons un exemple, sur mon dashboard de serveur Linux, la mémoire utilisée :
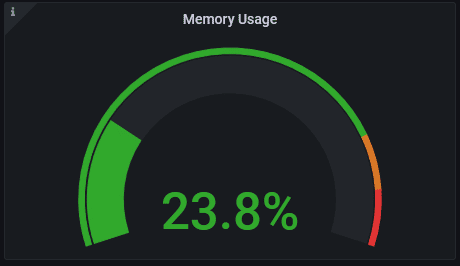
Comment est "fabriqué" ce graphe? Nous pouvons le voir en cliquant sur la petite flèche à côté du titre puis sur "Explore".
Sur la nouvelle fenêtre, vous avez en haut le code qui fait la requête ET la transformation des données et en bas, une représentation des données reçues. Pour cet exemple, le code est :
100 -
(
avg(node_memory_MemAvailable_bytes{job="integrations/node_exporter", instance="hostname"}) /
avg(node_memory_MemTotal_bytes{job="integrations/node_exporter", instance="hostname"})
* 100
)
On est donc ici face à une opération arithmétique : 100 - la moyenne (avg pour "Average") de la mémoire disponible du noeud (node_memory_MemAvailable_bytes) issue de l'instance "hostname", issue du "job" integrations/node_exporter divisé par la moyenne de la mémoire totale du noeud issue de l'instance "hostname", issue du "job" integrations/node_exporter x 100.
Cette requête est spécifique à une source de donnée Prometheus, en effet, on y retrouve deux termes spécifique à ce logiciel : instance et job. Une instance est le point de terminaison que vous monitorez (ici donc mon serveur Linux, déterminé par son nom d'hôte) et un job est un élément qui réalise un relevé de métrique donné.
Ces éléments apparaissent dans le fichier de configuration de l'agent Grafana :
logs:
configs:
- name: integrations
scrape_configs:
- job_name: integrations/node_exporter_journal_scrape
journal:
max_age: 24h
labels:
instance: hostname
job: integrations/node_exporterDans la fenêtre de l'exploreur, si vous basculez le switch sur "Builder" en haut à droite, vous verrez la même requête mais déconstruite :
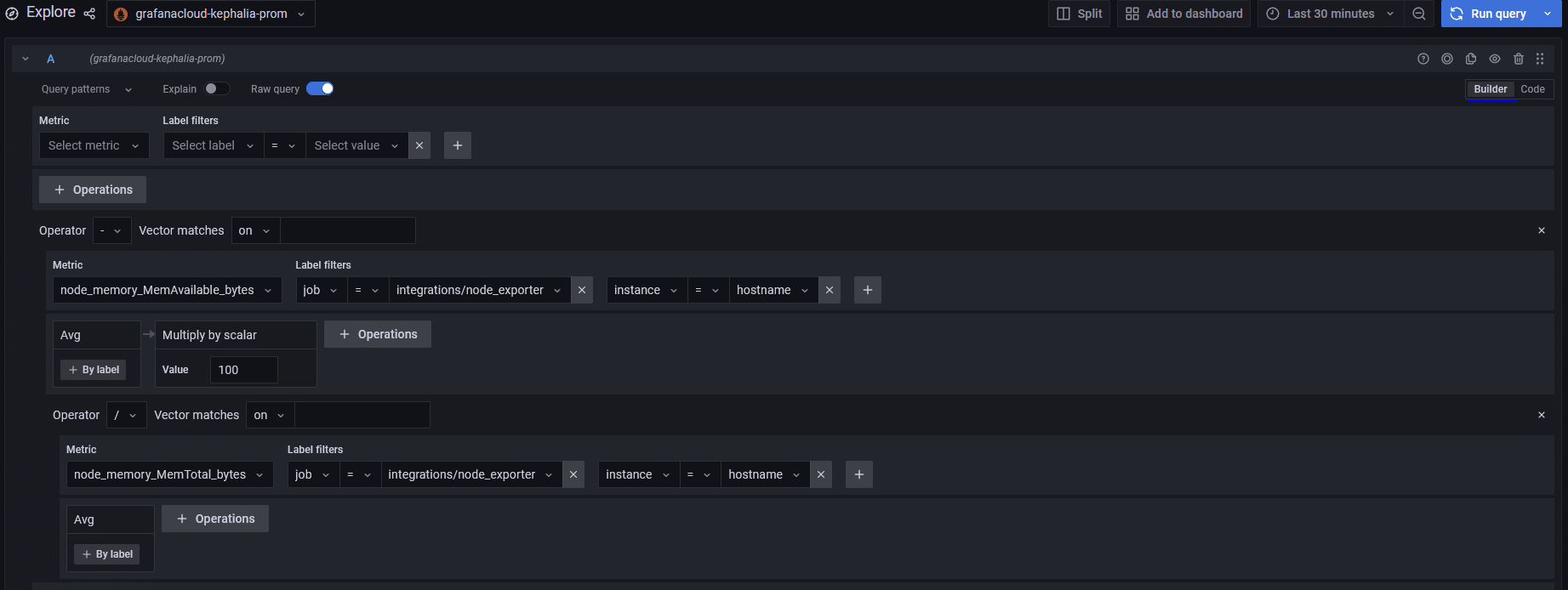
On aperçois les éléments suivants :
- Metrics : la métrique requêtée, ici "node_memory_MemAvailable_bytes"
- Label Filter : les filtres pour cette requête (car il peut y avoir plusieurs métriques qui "répondent" à cette requête). Ici le filtre est positionné sur "job" et on spécifie comme job integrations/node_exporter; puis également l'instance.
Puis viens en dessous la partie "transformation" :
- Avg : le type de transformation, ici moyenne
- Multiply by scalar : la valeur de la multiplication, ici 100
Viens ensuite un opérateur, ici la division avant la définition de l'autre métrique.
Un petit switch en haut de la fenêtre "Explain" permet d'afficher une petite explication sur chaque partie de la requête, pratique quand on débute!
B. Création de l'alerte
Bon, maintenant que nous avons compris comment cela fonctionne, il est temps de créer notre alerte.
Pour cela, cliquez sur l’icône en forme de cloche à gauche, et nous y voilà :
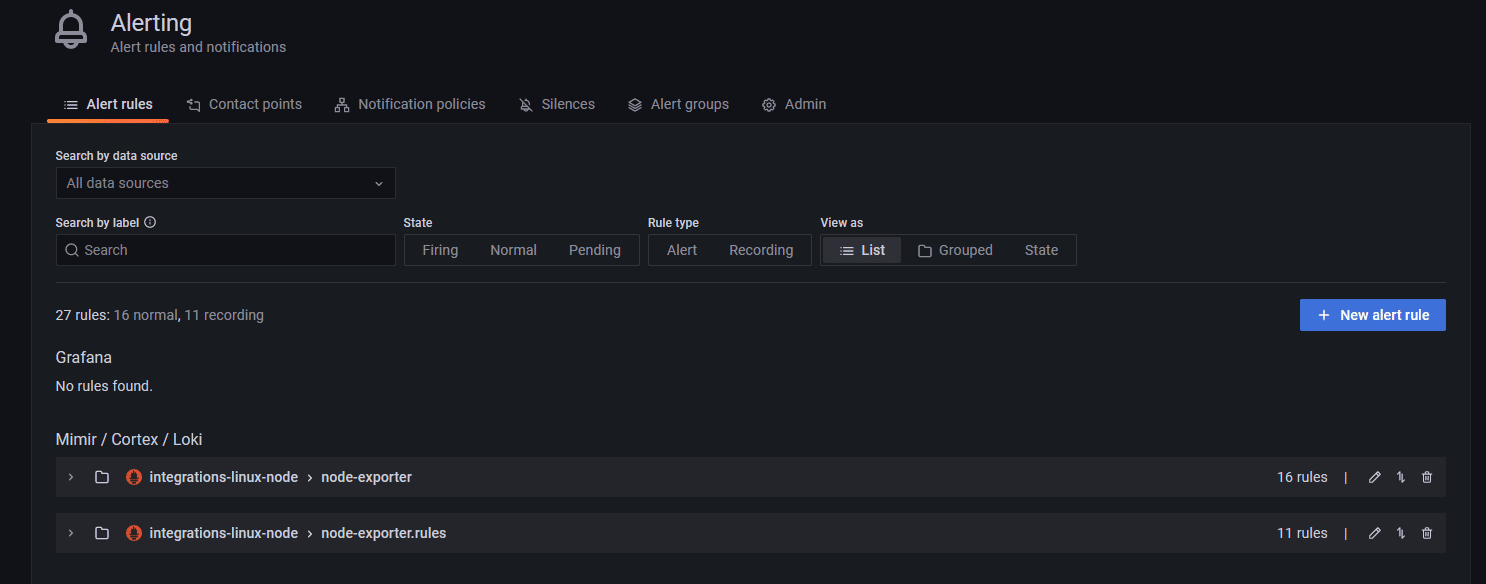
Pour ma part, je constate qu'il y a déjà 27 règles d'alerte définies, ce sont des alertes Loki crées par défaut sur notre source de données issues de Prometheus, donc rédigées en PromQL qui est le langage de requête spécifique à ce logiciel.
Si vous déroulez la partie "node-exporter" et la première règle par example (NodeFilesystemAlmostOutOfSpace), on peut voir ce code-ci :
(
node_filesystem_avail_bytes{job="integrations/node_exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="integrations/node_exporter",fstype!="",mountpoint!=""} * 100 < 5
and
node_filesystem_readonly{job="integrations/node_exporter",fstype!="",mountpoint!=""} == 0
)
Cette alerte est déclenchée lorsque l'espace disque est inférieur à 5%.
Nous allons donc créer une alerte pour la mémoire, basée sur ce que nous avons vu plus haut.
Tout d'abord, cliquez sur "+New alert rule" en haut à droite, vous serez redirigé sur la fenêtre de création :
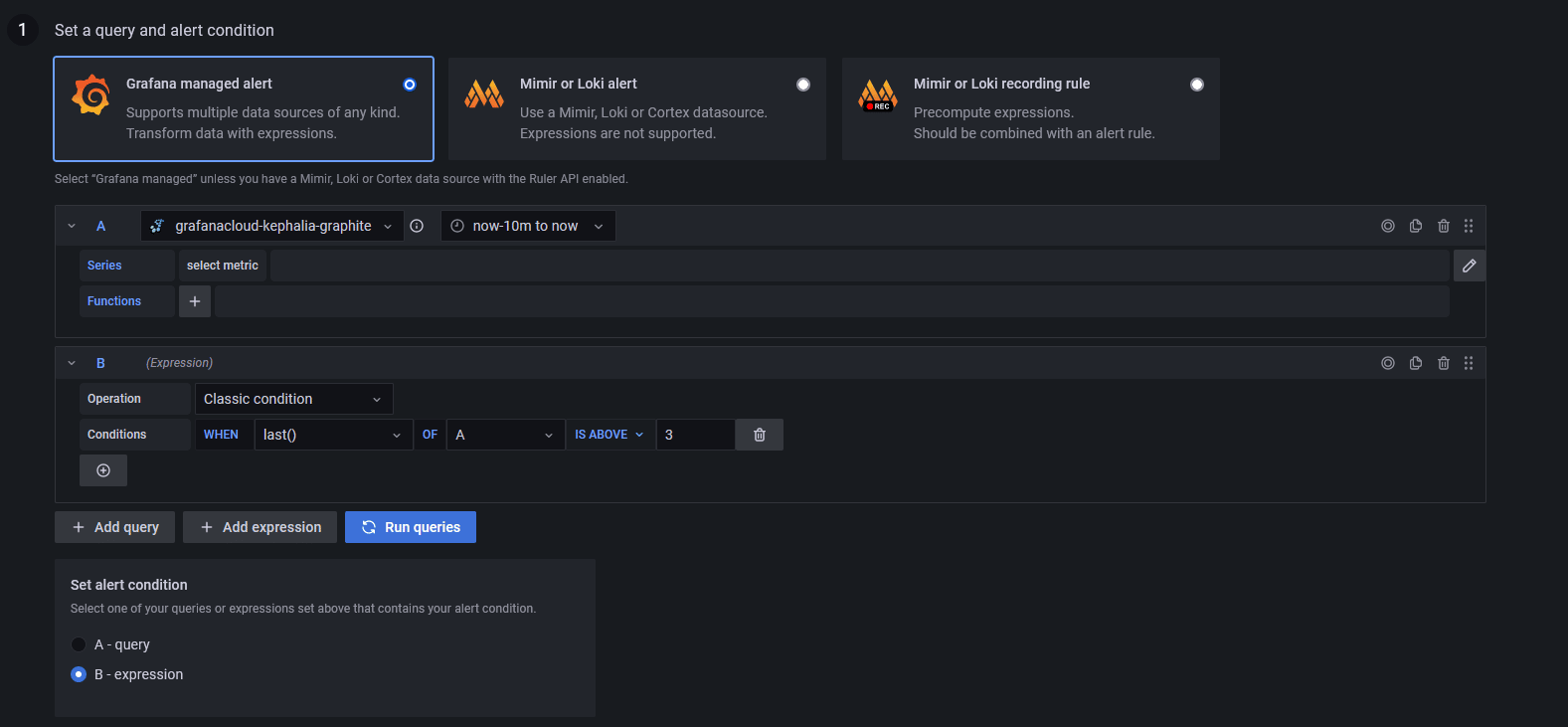
Par défaut, le type d'alerte est "Grafana Managed Alert", qui à l'avantage de s’adapter à tout type de source de données. Comme nous utilisons des données issues de Prometheus, nous pouvons sélectionner "Mirmir or Loki alert".
Ici, vous pouvez faire appel à un explorateur de métriques si vous ne savez pas quoi chercher, pour nous, nous connaissons la requête pour la mémoire :
100 - ( avg(node_memory_MemAvailable_bytes{job="integrations/node_exporter", instance="hostname"}) / avg(node_memory_MemTotal_bytes{job="integrations/node_exporter", instance="hostname"}) * 100 )
Nous allons simplement ajouter un "> 90", ce qui déclenchera une alerte lorsque la mémoire dépassera les 90% d'utilisation. Une fois la règle inscite dans le champ prévu à cet effet. Vous pouvez tester en cliquant sur "Prewiew alert" :
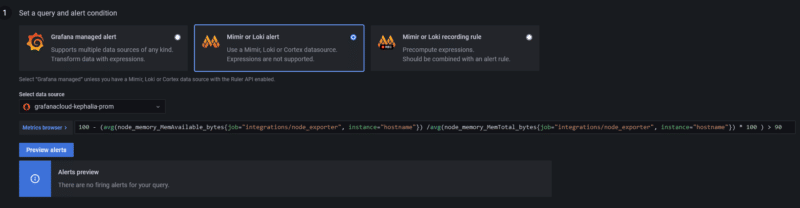
Vous deviez avoir la même réponse que moi, à savoir qu'il n'y a rien à déclencher. Normal me direz-vous puisque mon serveur se porte comme un charme, je vais donc le titiller un peu pour voir si l'alerte se déclenche bien.
Note : à ne pas faire sur un serveur de production!!
Pour augmenter l'utilisation de la mémoire rapidement, une simple commande "tail" avec une limite de mémoire :
</dev/zero head -c 1932735283 | tail
Le périphérique "/dev/zero" est un faux lecteur qui renvoi des données ASCII NULL (0x00), je l'utilise donc, avec une limite de 1,8 Go (attention, ici la valeur est en octets!!) et je renvoie tout cela à tail, donc en mémoire vive.
Peu de temps après, voici ma jauge de mémoire :
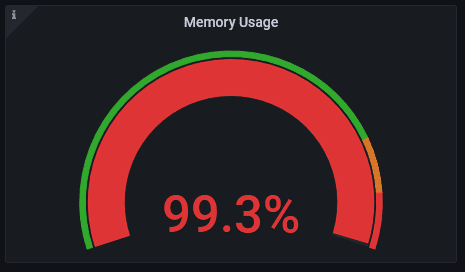
Ouch! Mais est-ce que mon alerte fonctionne? Pour cela, il suffit de recliquer sur "Preview Alert" :

Là, j'ai un résultat, et si je survole la bulle d'info, je constate bien une valeur à 99.5%, mon alerte fonctionne correctement!
Il me reste donc à renseigner les autres paramètres, comme la durée pendant laquelle cet état déclenchera l'alerte, je la positionne à 30 secondes. C'est à dire que si cet état dure 20 secondes, alors l'alerte sera déclenchée.
Je lui donne ensuite un nom et l'ajoute au groupe d'alerte existante car elles me conviennent bien (ça, vous faites comme vous voulez) et une petite description :
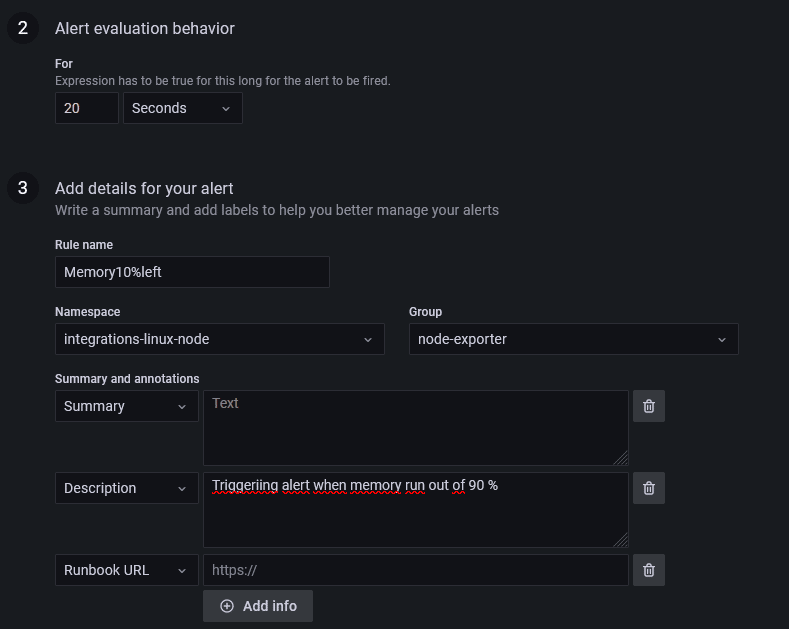
Enfin, il est possible de donner une étiquette à son alerte, notamment au niveau de la sévérité. Je décide d'indiquer une sévérité critique pour cette alerte :
Rien d'obligatoire, l'alerte sera déclenchée tout de même, cet étiquetage est pratique si on scrape les alertes par ailleurs ou qu'on les redirige vers un autre logiciel.
C. Destinataires
Une fois mes alertes crées, je dois définir à qui (ou quoi) elles serons envoyées. Tout cela se paramètre dans l'onglet "Contact Point" ou nous pourrons définir un modèle de message et des points de contacts qui le recevrons.
Pour les modèles de message, là encore c'est un autre langage, il s'agit de Go templating Language utilisé également par Prometheus.
Personnellement, je ne suis pas un pro de ce langage, je dois bien l'admettre, je vais donc me contenter du modèle de base, que je vais appeler "Default" :
{{define "Default"}}
{{range .Alerts}}
[{{.Status}}] {{range .Labels}} {{.Name}}={{.Value}}{{end}}
{{end}}}
{{end}}
Donc, sur l'onglet "Contact Point", je choisi le moteur d'alerte de Prometheus dans la liste déroulante, je lui donne un nom puis je colle le template :
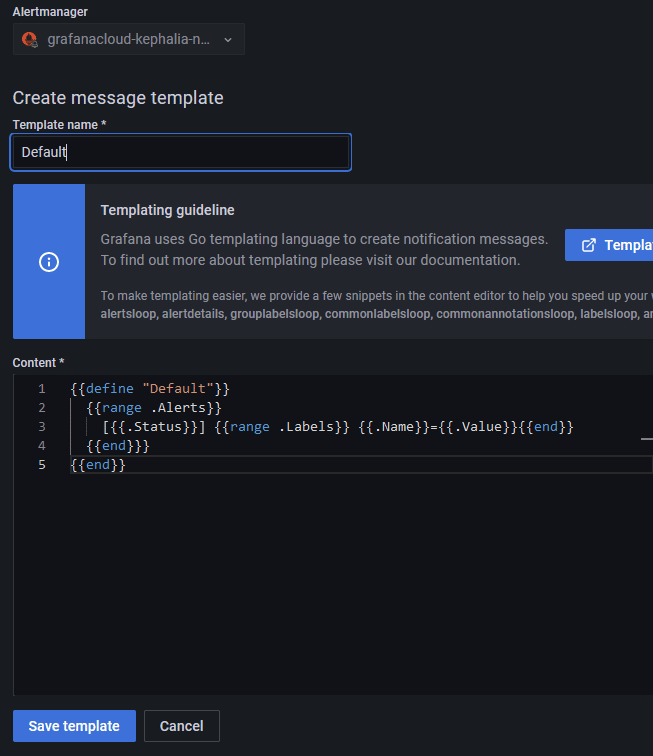
Il ne reste qu'à sauvegarder.
Toujours sur la page "Contact point", il faut aussi penser à renseigner les adresses mails ou les logiciels vers lesquels ont va pousser les alertes. Cela se passe dans la deuxième partie Contact points.
Ici, vous pourrez définir le type de point de contact dans la liste déroulante. Au passage, on constate que les alertes peuvent être envoyés vers plusieurs types de points, ce qui peut être pratique pour l'intégration; par exemple pour le moteur d'alerte Grafana on y retrouve Teams, Slack, Discord, etc... Comme nous avons choisi Prometheus, on est plus limité, je choisi les mails donc pas grave pour moi.
Un point de contact de type mail existe déjà mais est vide, nous allons donc ajouter l'adresse désirée :
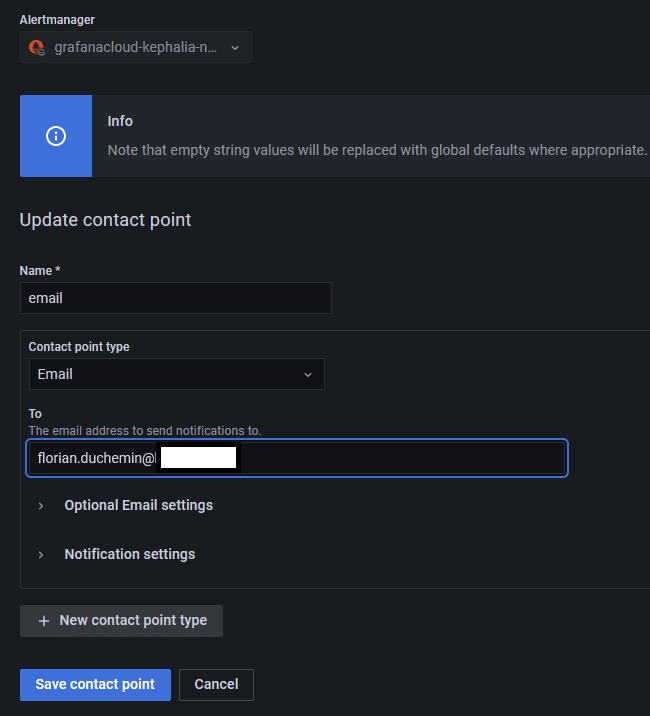
Les options avancées permettent de définir un nom d'expéditeur ou encore un serveur de mail. Pratique si on a du filtrage au niveau de la réception.
Nos alertes de base sont paramétrées, on teste ? Je relance ma commande sur mon serveur. Peut de temps après, je constate sur ma page des alertes qu'il y en a une qui est dans l'état "Firing" :
![]()
Et juste après, dans ma boite de réception :
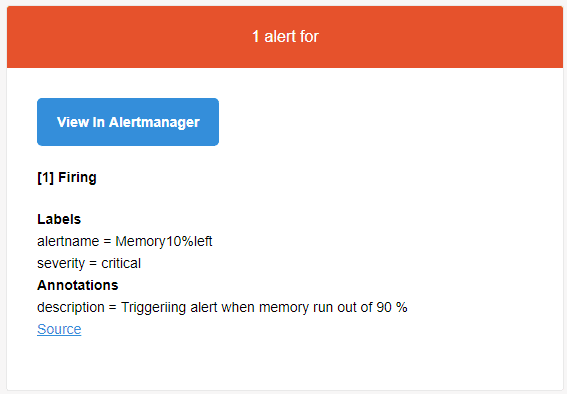
V. Conclusion
Dans ce tutoriel, nous avons vu comment simplement monitorer son serveur Windows ou Linux avec l'offre gratuite de Grafana Cloud et vu comment créer des alertes personnalisées. Il y aurait encore de nombreuses choses à couvrir, tant le sujet est vaste. Si cela vous intéresse, sachez que Grafana propose une "université" ou vous pourrez trouver des cours complet sur l'usage de celui-ci : university.grafana.com
Voici donc pour la partie cloud de Grafana, mais peut-être préférez-vous héberger votre serveur ? C'est possible, et ce sera le sujet d'un prochain tuto!
Bon monitoring !









Merci beaucoup pour ce tuto clair et détaillé !
Merci Antoine!
Hello,
Merci pour cet article complet. Petite question, possibilité d’utiliser l’agent telegraf avec la version cloud de Grafana ?
Charles
Bonjour Charles,
Oui, depuis peu, il est possible d’envoyer ses métriques depuis Telegraf vers Prometheus : https://grafana.com/docs/grafana-cloud/data-configuration/metrics/metrics-influxdb/push-from-telegraf/
L’utilisation est ensuite la même que dans le tuto.
Bonjour,
est-ce qu’il est pertinent de monitorer un parc d’ordinateur avec cet agent ?