
Réplication en temps réel Master/Slave MySQL
Sommaire
I. Présentation
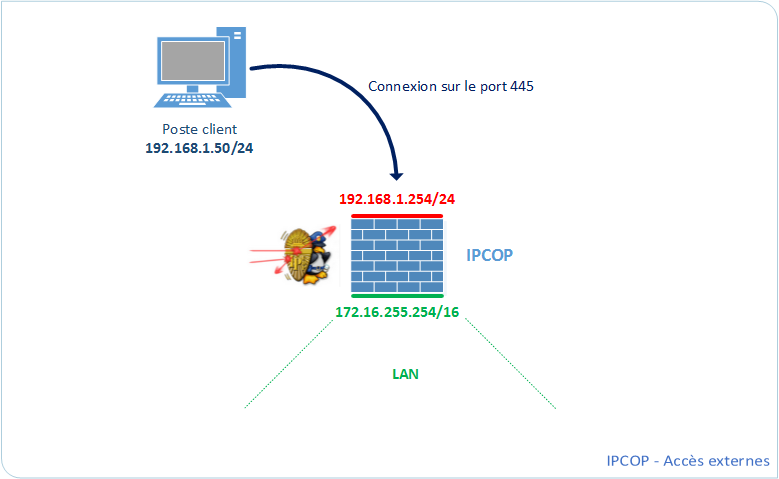
L'importance des serveurs de base de données et des bases de données elles même dans un système d'information est capital à son bon fonctionnement tant au niveau applicatif qu'au niveau des lectures par les serveurs web. C'est pourquoi il est important, dans une optique de sécurité et de disponibilité de l'information, d'avoir un processus à la fois de réplication des informations en temps réel mais aussi de tolérance de panne. Plus précisément, si un serveur dit "Master" tombe, un autre serveur "Slave" doit prendre le relais de manière immédiate et doit aussi avoir la dernière version des informations.
Dans ce tutoriel, nous allons apprendre à mettre en place une réplication des bases de données en temps réel entre un serveur dit "Master" qui va recevoir les processus d'écriture et de lecture et un serveur "Slave" qui se chargera de se mettre à jour selon les modifications faites sur le "Master" afin qu'il dispose des dernières versions des informations et qu'il soit ainsi prêt à prendre le relais en cas de défaillance du serveur principal.
Note : Ce tutoriel n'est valable que pour les versions de MySQL avant la 5.5. En effet, à partir de la 5.5, quelques détails changent dans la configuration des différentes machines Maitre/Esclave.
Il est important de savoir que plusieurs "Slave" peuvent être en place et peuvent pointer sur un "Master" afin d'avoir plusieurs niveau de "Fail-over".
II. Explication du principe de réplication en temps réel
Avant de mettre en place un tel processus, il est important de comprendre comment il fonctionne. On part du principe que le serveur MySQL "Master" et le serveur MySQL "Slave" démarrent avec exactement la même base de données qui seront identiques. Quand une réplication est active et que le serveur MySQL "Master" connait son rôle, il va écrire toutes les requêtes modifiant son contenu ("UPDATE", "DELETE", "INSERT INTO", ...) dans un fichier tiers binaire qu'il aura créé lors de son démarrage, dans un second temps il enverra à son où ses "Slave" un événement de réplication que le "Slave" stockera dans son fichier binaire appelé "mysql-relay-bin". De son coté, le serveur MySQL "Slave" qui aura dans ses paramètres l'adresse, le port, les identifiants ainsi que des informations sur le fichier binaire en question ira lire ce fichier en local et effectuera en temps réel les mêmes commandes sur sa propre base de données.
Il est important de savoir que l'on peut choisir de synchroniser une, plusieurs ou toutes les bases de données d'un serveur MySQL. Le nom de ces bases doit être mis dans la configuration, ce que nous verrons un peu plus tard. Il est aussi à savoir que les processus d'écritures ne doivent se faire uniquement sur le serveur MySQL Master. Si l'on commence à écrire sur le "Slave" et que le "Master" ne contient pas cette modification, la synchronisation et la réplication seront faussées. Voici un schéma expliquant brièvement ce processus :
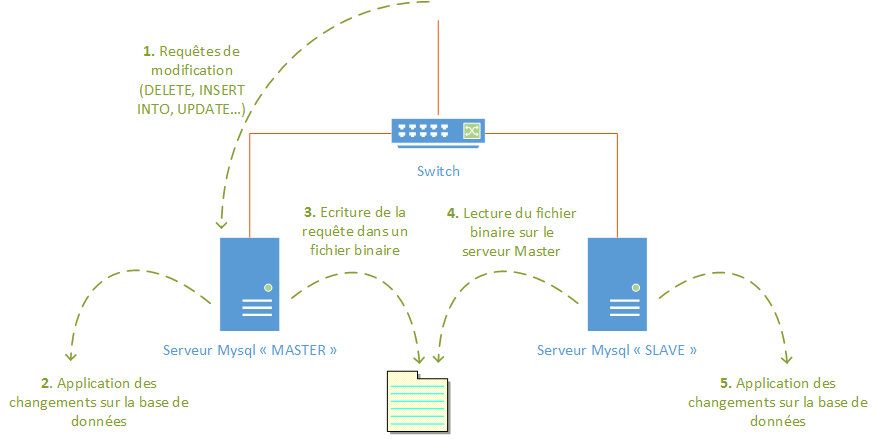
III. Mise en place de l'architecture
Note : Cette partie explique la mise en place basique de l'architecture, des serveurs MySQL, d'une base de données "test" et des accès nécessaires à la réplication. Passez directement à la partie "IV. Configuration du master" si vos serveurs, bases de données et accès sont déjà en place.
Lors de ce tutoriel, nous allons suivre le schéma suivant :
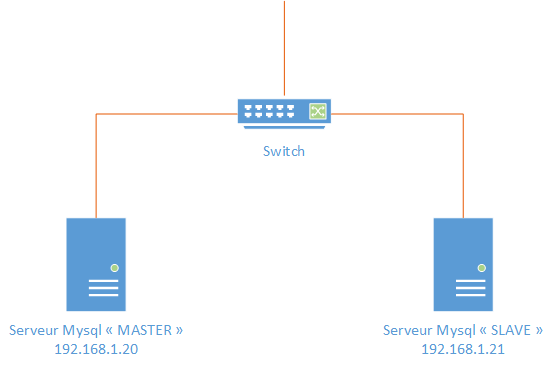
Notre serveur MySQL "Master" aura l'IP 192.168.1.20 et notre serveur MySQL "Slave" aura l'IP 192.168.1.21. Les écritures depuis les serveurs web ou toute autres applications se feront donc directement sur le "Master" et jamais sur le "Slave" (hormis si le "Master" est défaillant, ce que nous verrons plus tard). Nous allons sur nos deux serveurs installer MySQL;
# On met à jours nos paquets apt-get update # On installe le serveur MySQL apt-get install mysql-server
Pour notre serveur "Slave" puisse recevoir les événements de réplication envoyés par le serveur "Master" par un processus expliqué plus tard, nous devons ouvrir notre serveur MySQL à l'écoute sur l'extérieur puis créer un utilisateur qui aura les droits de réplication et de lecture sur les bases voulues :
# Sur le Master vim /etc/mysql/my.cnf
![]()
On met à l'option "bind-address" qui sera l'adresse d'écoute du service MySQL l'adresse IP du serveur "Master" pour qu'il se mette à écouter les informations provenant de l'extérieur sur MySQL. On procède ensuite au redémarrage de notre service MySQL pour qu'il puisse prendre en compte la nouvelle configuration :
service mysql restart
Il nous faut maintenant créer un utilisateur qui sera utilisé par le serveur "Slave" pour venir récupérer les informations afin de procéder à la réplication en temps réel :
# On se connecte au serveur MySQL en ligne de commande mysql -u root -p # On créer l'utilisateur en question CREATE USER "slave"@"192.168.1.21" IDENTIFIED BY "< password >" ;
Nous allons profiter d'être en ligne de commande sur notre serveur pour créer une base de donnée "test1" que nous allons utiliser pour tester la replication :
CREATE DATABASE test1; USE test1; CREATE TABLE T1 (ID INT Not Null) ENGINE = InnoDB CHARACTER SET latin1 COLLATE latin1_bin;
On insert ensuite une première valeur dans notre table :
INSERT INTO T1 (ID) VALUES (1);
On va ensuite afficher notre table pour confirmer sa création :
select * from test1.T1 ;

IV. Configuration du master
Note : Pour mieux comprendre et déboguer, pensez à activer vos "error-logs" MysQL avec ce tutoriel.
Maintenant que notre environnement est prêt, nous pouvons passer à la configuration du serveur MySQL "Master". On commence donner les droits de réplication à notre utilisateur. Les droits "REPLICATIONS SLAVE" donnent le droit à l'utilisateur de recevoire les évenements de réplication sur son fichier binaire ("mysql-relay-bin") où le serveur "Master" écrit les modifications sur la ou les bases de données :
# On se connecte au serveur MySQL Master en ligne de commande mysql -u root -p Grant replication slave on *.* to "slave"@"192.168.1.21" ; FLUSH PRIVILEGES ;
Nous allons regarder une première fois l'état de notre serveur MysQL "Master" en effectuant cette commande dans le terminal MySQL :
SHOW MASTER STATUS;
Vous devriez avoir une réponse de ce type :
![]()
On voit ici que notre serveur ne connait pas son rôle car nous ne lui avons pas dit de devenir un "Master". Nous allons donc aller quelque peu modifier sa configuration dans le fichier "/etc/mysql/my.cnf". On doit commencer par indiquer un identifiant à notre serveur. Il faut savoir que dans le système Master/Slave MySQL. Le serveur ayant le plus petit identifiant devient un "Master". Nous allons donc lui mettre l'identifiant "1" dans la partie "[mysqld]" de la configuration :
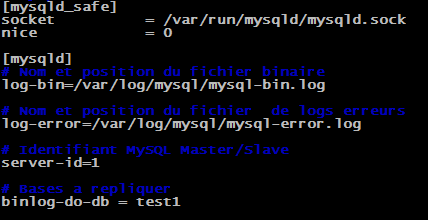
Pour que le service MySQL redémarre correctement, il faut créer les fichiers de logs pour qu'il puisse écrire dedans :
touch /var/log/mysql/mysql-bin.log touch /var/log/mysql/mysql-error.log chown mysql -Rf /var/log/mysql/
On redémarre ensuite notre serveur MySQLpour que les changements soient pris en compte :
service mysql restart
On va ensuite vérifier à nouveau l'état de notre Master :
# On se connecte au serveur MySQL en ligne de commande mysql -u root -p SHOW MASTER STATUS;
Nous aurons alors de nouvelles informations :

On a donc une information sur le nom du fichier "bin" dans lequel le serveur écrit les modifications sur les bases de données, la position de celui-ci et la ou les bases de données qui sont répliquées en temps réel. La quatrième colonne pourrais contenir les noms de bases de données à ne pas répliquer.
Notre serveur "Master" est maintenant prêt. Il ne faut plus que nous ayons d'écriture sur la base de données à présent car nous allons passer à la configuration du serveur "Slave". On bloque donc temporairement les écritures sur la base de données.
FLUSH TABLES WITH READ LOCK;
V. Configuration du slave
Nous allons maintenant passer à la configuration du serveur MySQL "Slave". Pour un rapide rappel, celui-ci va aller lire le fichier binaire du "Master" pour effectuer sur ces propres bases de données les mêmes modifications. On va donc dans un premier temps importer la base de données que nous souhaitons répliquer du "Master" vers le "Slave". Le but ici est que les deux serveurs démarrent avec la même version de la base de données :
# Sur le Master # On sauvegarder notre base de données dans un fichier mysqldump -u root -p --database test1 > test1.sql # On envoie ce fichier sur le Slave scp test1.sql [email protected]:/root # Sur le Slave # On importe la base de données dans notre service MySQL mysql -u root -p < test1.sql
Le "Master" et le "Slave" ont maintenant la même version de la base de données. Nous allons maintenant informer notre serveur "Slave" de l'existence du "Master" et lui dire d'aller lire les modifications à faire sur la base de données dans le fichier binaire reçu par le "Master". On va pour cela dans la configuration du service MySQL de notre "Slave" pour y ajouter ces lignes :
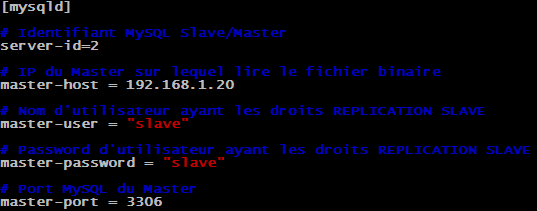
On redémarre ensuite notre serveur pour que les changements soient pris en compte :
service mysql restart
Nous allons maintenant nous connecter à notre serveur MySQL "Slave" pour lui renseigner le nom et la position du fichier binaire sur le serveur (ce sont les informations que l'on obtient en faisant un "SHOW MASTER STATUS;" sur le serveur "Master") :
# On se connecte au serveur MySQL en ligne de commande mysql -u root -p STOP SLAVE; CHANGE MASTER TO MASTER_LOG_FILE='< fichier binaire >', MASTER_LOG_POS=< position du fichier binaire >; # On redémarre notre status de slave start slave;
Nous allons ensuite voir les informations que nous avons sur notre "Slave" avec la commande suivante :
show slave status \G;
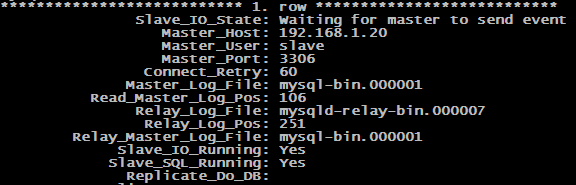
Nous voyons bien ici les informations de connexion du "Slave" vers le "Master". Pour être certain que la réplication s'effectue bien, les valeurs "Slave_IO_Running" et "Slave_SQL_Running" doivent être à "Yes". On remarque en première ligne également le "Slave_IO_State" qui est "en attente d'un événement du Master" ce qui indique bien que c'est au "Master" d'envoyer les événement de réplications et que pour l'instant aucun événement n'est en cours.
Notre "Slave" est maintenant bien synchronisé pour la réplication. Nous allons néanmoins faire un test basique pour nous en assurer.
VI. Test de la réplication en temps réel
Nous n'avons pour l'instant qu'une valeur dans notre table "test1.T1" créée dans la partie "III. Mise en place de l'architecture". Nous allons maintenant tester la
réplication en temps réel de notre base de données. On ajoute une valeur à notre base de données du coté du "Master" : # Sur le Master mysql -u root -p use test1; INSERT INTO T1 (ID) VALUES (2);
On va ensuite directement vérifier du coté du "Slave" si la donnée ID "2" a bien été répliquée :
# Sur le Slave mysql -u root -p use test1; select * from T1;
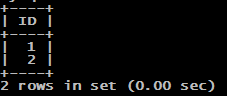
La donnée a donc bien été répliqué, nous sommes maintenant certains que la réplication s'effectue correctement entre le "Master" et le "Slave". Pour une meilleur compréhension, nous pouvons également aller voir le contenu du fichier binaire coté "Master" qui se situe dans "/var/log/mysql/" :

Le fichier n'est pas totalement lisible mais on remarque quand même la présence de la requête de modification de la base de données effectuée. On sait donc que le "Slave" lit ce fichier en local qui se situe dans "/var/lib/mysql" et qui possède le même contenu que le fichier coté "Master" puis effectue les mêmes requêtes sur les bases à repliquées de son coté.
VII. Simulation de panne, récupération et remise en ordre du master
Nous allons maintenant simuler une défaillance du serveur Maitre. On va donc dire que les procédures d'écriture se font maintenant sur le serveur "Slave" (192.168.1.21) et qu'il possède donc la dernière version des données. Après avoir remis en état de fonctionnement le serveur "Master" MySQL. Nous allons remettre en place notre réplication Master - Slave.
Note : Pour simuler cette panne, nous allons juste faire un "service mysql stop" sur le "Master" et nous allons ajouter une donnée dans notre base de test coté "Slave" avec la commande "insert into T1 (ID) Values (3)".
La première évaluation à faire est que nous devons mettre la dernière version de la base de données qui est actuellement sur le "Slave" sur le "Master". On effectue donc une sauvegarde de la base de données sur le "Slave" dans un fichier :
# Sur le Slave mysqldump -u root -p --database test1 > test1.sql # On eteind temporairement l'état SLAVE du service MySQL mysql -u root -p STOP SLAVE ;
On va ensuite transférer cette base de données sur le serveur "Master" :
scp test1.sql [email protected]:/root
On va ensuite réimplanter sur le "Master" la dernière version de la base de données que nous venons d'importer depuis le "Slave" :
# Sur le Master service mysql start mysql -u root -p < /root/test1.sql
Étant donné que le serveur a redémarrer, il faut chercher le nouveau nom du fichier binaire et sa position pour le renseigner au "Slave" :
# Sur le master mysql -u root -p SHOW MASTER STATUS;
Une fois les informations récupérées, on les renseignes au "Slave" puis on le redémarre :
# Sur le Slave mysql -u root -p CHANGE MASTER TO MASTER_LOG_FILE='< fichier binaire >', MASTER_LOG_POS=< position du fichier binaire >; START SLAVE ;
La réplication est maintenant relancée








Merci pour ces connaissances mais j’aimerai connaitre les configurations ajoutés lors de réplication avec mysql 5.5,5.6 et plus encore.(j’espere qu’un mail me sera envoyé car je suis tombé sur votre site lors de mes recherches).
Merci
merci pour ce tuto en faite j’aimerais bien savoir la signification au niveau de la requête fichier binaire et sa position ?
Bonjour, J’ai bien suivi ce tutoriel et je le trouve très bien mais je reste bloqué dans la configuration du Slave.
Après avoir entrer la commande « service mysql restart », lorsque je veux me connecter a Mysql j’obtiens le message suivant :
« Can’t connect to local MySQL server through socket ‘/var/run/mysqld/mysqld.sock’ (2) »
Merci de votre aide
Bonjour, j’ai bien suivi ce tutoriel mais lorsque je tape la commande :
« mysql -u root -p »,
j’obtiens ce message :
« ERROR 2002 (HY000): Can’t connect to local MySQL server through socket ‘/var/run/mysqld/mysqld.sock’ (2) »
Je suis entrain de configurer le slave.
Merci de vos réponses
Bonjour, après configuration du slave, le redémarrage de la base de données est impossible, comment résoudre ce problème? je test sur un debian et ma version de base de données est 5.5.
votre aide serait d’un grand secours, c’est pour un sujet de stage
cordialement
Bonjour,
Pour ceux qui ont un souci avec le slave, faites les confs suivantes.
Après avoir importé la BD du maitre sur le slave, modifier le fichier de config du slave:
#vi /etc/mysql/my.cnf
server-id = 2
relay-log = /var/log/mysql/mysql-relay-bin.log
log_bin = /var/log/mysql/mysql-bin.log
binlog_do_db = test1
puis redémarrer le service mysql
#service mysql restart
connectez vous sur le mysql maitre
#mysql -u root -p
SHOW MAITRE STATUS;
retenez les info sur le tableau
connectez vous sur le mysql slave
#mysql -u root -p
mettre les info du maitre en tapant les commandes suivantes:
CHANGE MASTER TO MASTER_HOST=’192.168.1.20′,MASTER_USER=’slave’, MASTER_PASSWORD=’password’, MASTER_LOG_FILE=’mysql-bin.000001′, MASTER_LOG_POS= 106;
START SLAVE;
SHOW SLAVE STATUS\G
ou
SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; SLAVE START;
Merci Amadou SOW !!
La commande SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; m’a sauvé 🙂
Pour la version 5.7 de mysql
cette ligne est à éviter :
relay-log = /var/log/mysql/mysql-relay-bin.log
Bonsoir mes chères
je suis Olin un étudiant en master en administration système et réseau. Je voudrais travailler sur la réplication des bases de donnée comme thème de fin de stage.
Mon encadreur m’a demander de recherche quels sont les aspects à prendre en compte avant de mettre sur pied un système de replication de base de données et je suis vraiment perdu. La seule piste que j’ai c’est juste la contrainte de connectivité continu entre les différents sites sur lesquels la replication sera propagée.
S’il vous plait je voudrais quelque avis de professionnels comme vous.
Merci
Bonjour,
Superbe tuto, concernant l’ajout d’un deuxième slave SQL la procédure est elle identique ?
Pour afficher en clair le contenu d’un fichier binlog ou d’un relaylog on peut utiliser la commande mysqlbinlog :
# mysqlbinlog -v /var/log/mysql/mysql-relay-bin.000001
La valeur du server-id ne sert pas à désigner un master ou un slave. Il suffit qu’elle soit unique pour chaque serveur MySQL en réplication. Ce qui donne à un serveur MySQL le rôle de slave c’est la commande CHANGE MASTER TO.
Le master lui ne connait pas ses slaves.
Comment le dialogue se fait entre les deux serveurs perso je pense que tout est en clair,
il me semble qu’il faudrait imposer une connection sécurisé comme ici https://www.it-connect.fr/configurer-le-ssl-pour-securiser-mysql%EF%BB%BF/ entre les deux serveur non ?