

Qu’est ce qu’un SPOF – Single Point of Failure ?
Sommaire
I. Présentation
Dans ce billet, nous allons nous pencher sur le terme SPOF, qui est l'acronyme de Single Point of Failure. SPOF peut être traduit en français par point individuel de défaillance. Nous allons également voir en quoi les SPOF sont importants dans le domaine de la sécurité. J'ai eu envie de rédiger un billet à ce propos après avoir visionné la conférence "JCSA2012 - Tutoriel Stéphane Bortzmeyer "Sécurité des noms de domaine" dans laquelle ce dernier parle brièvement des SPOF DNS.
II. Single Point Of Failure
Un point individuel de défaillance est, comme son nom l'indique, un point qui peut être identifié dans une infrastructure ou une architecture donnée comme étant critique pour cette infrastructure dans le cas où celui-ci vient à défaillir. Ce n'est pas un concept propre aux architectures informatiques, tous les autres domaines mettant en place des réseaux au sens infrastructure sont déjà bien familiers avec ce concept et depuis plus longtemps que dans le domaine informatique, par exemple pour les réseaux de gaz, d’électricité, d'eau ou encore les réseaux routiers.
Le principe d'identification d'un point réseau comme étant un SPOF est celle d'un point où tout finit par passer et qui est critique pour l'infrastructure. Entendre par là qu'aucun autre moyen de fournir un service ou de joindre une partie d'un réseau ou d'Internet n'est possible si ce point tombe en panne. La définition, plus ou moins officielle, est la suivante :
Tout élément de configuration pouvant causer un incident lorsqu’il tombe en panne, et pour lequel une contre-mesure n’a pas été implantée. Un point de défaillance unique peut tout aussi bien être une personne, ou une étape d’un processus ou d’une activité, qu’un composant d’une infrastructure informatique.
Plus simplement, un SPOF est un endroit où si ce point tombe, tout le reste tombe également.
III. Savoir les identifier
On parle souvent de "maillon faible de la chaîne" lorsque l'on met en avant un SPOF, car c'est en effet une partie du réseau qui peut être identifiée comme particulièrement vulnérable et mettant en danger le reste de l'infrastructure selon son importance et son rôle. Voici un schéma simplifié d’infrastructure réseau que nous allons utiliser dans un premier temps :
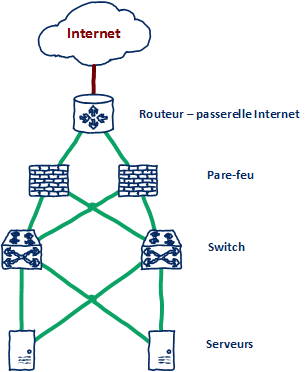
Ici, on voit que certains éléments sont redondés sur le réseau, néanmoins, on remarque qu'un seul point est utilisé pour aller sur Internet, si ce point tombe, aucun autre n'est présent pour prendre le relais, le SPOF dans ce schéma est donc le routeur qui lie le LAN à Internet. Ce qui est intéressant, c'est que les SPOF ne sont pas spécifiques aux réseaux, il faut avoir un point de vue général du SI pour essayer d'identifier tous les SPOF possibles... Les SPOF peuvent être identifiés tout au long d'une chaîne de traitement ou de circulation d'un flux, c'est ce qui fait que les SPOF requièrent une attention particulière au sein des SI ainsi qu'une connaissance précise de ceux-ci. Pour illustrer le contournement d'un SPOF, voici la dernière carte parue identifiant les câbles réseau sous-marins reliant les différents continents entre eux au niveau d'Internet.
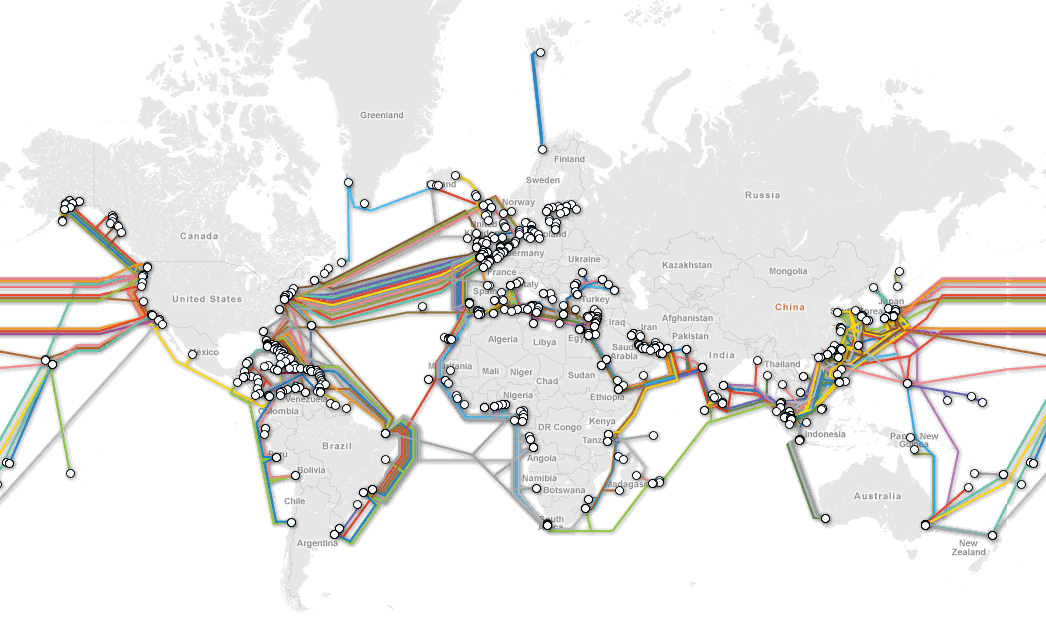
Bien que l'on puisse identifier des points névralgiques comme à New York ou en Égypte où beaucoup de câbles passent, on voit ici qu'aucun SPOF ne peut être identifié facilement, plus clairement, si un câble tombe ou vient à être défaillant, il est possible de repasser par un autre chemin pour joindre notre cible. Pour être plus familiers avec les SPOF, nous allons essayer d'identifier des endroits où les SPOF sont fréquents.
- Comme nous l'avons identifié plus haut dans notre schéma, un SPOF réseau va être un endroit dans l'architecture réseau où tout ou partie des flux vont passer sans avoir de chemin secondaire. Il s'agit le plus souvent d'un chemin situé dans le cœur du réseau ou vers Internet (routeur, passerelle ou pare-feu).
- Sur un serveur, il est possible d'identifier plusieurs SPOF qui sont le plus souvent physiques, on peut par exemple prendre l'alimentation qui est parfois unique sur les petits serveurs, mais systématiquement en double sur les serveurs un peu plus costauds. Quand une double alimentation est mise, il faut être attentif à ne pas brancher les deux sur la même source d'énergie, mais à bien avoir deux circuits électriques différents et indépendants de bout en bout. Également, une liaison câblée en Ethernet entre un switch et un serveur peut être identifiée comme un point de défaillance unique, on peut alors imaginer mettre deux câbles vers deux switchs différents.
- Il peut être intéressant d'avoir plusieurs serveurs qui sont en redondance les uns par rapport aux autres, seulement si ces serveurs sont sur le même rack ou dans la même salle, il est fort possible qu'une coupure d’électricité ou qu'une coupure réseau affecte tous les serveurs en même temps, rendant inutile la redondance mise en place.
- De la même manière lorsque l'on choisit différents fournisseurs d'accès à Internet, il est judicieux de vérifier par où passent les câbles reliant le SI aux différents FAI. Si les câbles passent tous au même endroit physiquement ou par les mêmes points de collectes, c'est que nous sommes en présence d'un SPOF, on peut alors croiser le fameux "coup de pelleteuse" qui peut mettre à mal tout un SI même si l’on possède des FAI différents.
- Un autre exemple intéressant mis en avant par Stéphane Bortzmeyer lors d'une conférence sur la sécurité des noms de domaines est qu'en Californie, une grande faille sismique existe (Faille de San Andreas). Quand des Datacenters sont construits, les ingénieurs et architectes doivent veiller à ne pas les construire sur la même faille sismique, car même si les deux Datacenters sont séparés de plusieurs centaines de kilomètres, ils peuvent se situer sur la même faille et donc tomber en même temps lorsque cette faille tremblera.
On voit donc dans ces différents exemples qu'il faut avoir une vue à la fois très générale et très détaillée d'un SI pour identifier tous les Single Point Of Failure présents dans celui-ci. Tous les SPOF ne sont pas forcément à supprimer au sein d'un système d'information, cela coûte souvent cher et est parfois inutile quand les éléments situés sur la chaîne de traitement de l'information ne sont pas vitaux. Toutefois, quand un élément est jugé vital, il convient de vérifier et de supprimer les SPOF de bout en bout.
Au sein des systèmes d'information, on essaie de rapprocher le plus possible les SPOF des utilisateurs. Cela permet, en cas de défaillance, de faire que celle-ci impact le moins de monde possible. Plutôt que de mettre une redondance sur les switchs situés en couche d’accès, on préférera donc redonder les switchs des couches distributions ou les sorties Internet.
IV. L'importance de l'identification des SPOF
L'identification d'un SPOF dans une architecture informatique requiert d'avoir une vue d'ensemble, mais précise de tout ce qui la compose. Un SPOF est un point critique pour une architecture informatique ou un LAN, car il peut rapidement être identifié comme une cible de choix pour mettre à mal un ensemble de machines ou un service. Sur l'architecture vue plus haut, on voit que l'administrateur a pris la peine de mettre en redondance certains éléments du réseau. La mise en redondance d'éléments comme des routeurs ou des serveurs offrant des services est de faire en sorte que si l'un tombe ou est surchargé, l'autre prenne le relais.
Connaissant ce principe de fonctionnement, un pirate expérimenté ne perdra pas son temps à attaquer des équipements redondés, seulement s'il a identifié le SPOF qui est le routeur, il deviendra une cible prioritaire, car faire tomber le routeur reviendra à faire tomber le reste de l'infrastructure qui deviendra injoignable. En sécurité informatique, la sécurité de l'ensemble est évaluée par la sécurité la plus basse évaluée sur chacun des composants, lorsque l'on entame des redondances pour mettre un service en mode "haute disponibilité", il est important de le faire sur toute la chaîne de traitement pour ne pas laisser apparaître de SPOF sur celle-ci.
V. Mise en place de contre mesure
Une fois que les SPOF sont identifiés, la plupart peuvent en général être supprimés par la mise en place de systèmes de redondance ou de haute disponibilité, dit "HA" pour High Availability. On parle alors généralement de Fail-Over, plus rarement de Load-Balancing qui est un terme se rapprochant plus de la répartition de charge.
On peut également voir plus loin en identifiant des SPOF logiciels qui font que si un logiciel utilisé par tous les serveurs d'un cluster de redondance comporte une vulnérabilité, aucun autre système ne peut venir nous aider à nous couvrir de cette vulnérabilité. Pour prendre un exemple plus concret, si nous disposons de trois routeurs pour une sortie de réseau et que ceux-ci sont en redondance, si une faille de sécurité est découverte sur ces systèmes et qu'elle permet de les faire tomber en quelques secondes, alors on peut identifier un SPOF qui fera qu'aucun autre système ne pourra prendre le relais si ce système vient à défaillir.
Il est alors envisageable d'utiliser différents systèmes pour faire une même action. Cependant, il n'est pas toujours possible de mettre des systèmes, parfois concurrents, en redondance et de les faire travailler ensemble. Il faut généralement pour cela qu'un protocole de redondance standardisé ait été mis en place, on peut prendre VRRP (Virtual Router Redundancy Protocol) par exemple qui permet la mise en redondance de différentes passerelles et qui est la version standardisée du protocole propriétaire Cisco HSRP (Hot Standby Router Protocol), celui-ci ne fonctionnant qu'entre éléments actifs Cisco. Cela nécessitant du temps, de l'investissement et des compétences supplémentaires !
Enfin, la mise en place de contre-mesures passe également par le fait de tester les technologies et les processus de Fail-Over mis en place. Il est en effet important d'être certain du comportement d'un élément du réseau mis en redondance lorsque le maître ou un pair vient à être défaillant. De la même manière, il est important de savoir si le retour à la normale de la situation après la remise sur pieds de l'élément défaillant se fait avec manipulation d'un technicien ou de façon automatique et les pertes de paquets ou de requêtes que cela peut générer.
Il faut également garder en tête que la mise en place de contre-mesures envers les points de défaillance individuels ont un certain coût, d'abord en matériel, mais également, car cela requiert, en fonction des technologies utilisées, des compétences spécifiques et du temps de maintenance et de mise en place. Il faut donc bien évaluer la criticité d'un service ou d'un serveur afin de juger si oui on non il est vitale et mérite une attention avancée pour supprimer les SPOF qui sont sur son chemin.










Annagrame -> Acronyme
Corrigé, merci 🙂
Hello,
Merci pour cet article très intéressant.