

Le protocole HTTP pour les débutants
Sommaire
I. Présentation
Dans cet article "Le protocole HTTP pour les débutants", je vous propose de découvrir le protocole HTTP avant d'étudier le protocole HTTPS au travers d'un prochain article ! Connaître le protocole HTTP est indispensable pour bien appréhender le fonctionnement du protocole HTTPS. Après une brève présentation de ce protocole, nous rentrerons dans le détail et nous finirons par une mise en pratique.

Le protocole HTTP, pour HyperText Transfer Protocol, est un protocole de communication client-serveur qui permet d'accéder à des ressources situées sur un serveur Web. Aujourd'hui, on lui préfère le HTTPS, dont le S signifie Secured, il s'agit d'une variante sécurisée du protocole HTTP et qui s'appuie sur les protocoles TLS pour chiffrer les échanges entre le client et le serveur.
Pour communiquer avec un serveur Web au travers du protocole HTTP, on s'appuiera sur un client HTTP. Au quotidien, ce client HTTP prend la forme d'un navigateur Internet (Firefox, Chrome, Edge, etc...), même s'il existe de nombreux outils, notamment en ligne de commandes, capable d'effectuer des requêtes Web.
Depuis les débuts de l'Internet, le protocole HTTP (et maintenant le HTTPS) est utilisé sur les serveurs Web, notamment pour héberger un site Internet, que ce soit un blog, un site vitrine, ou un site d'e-commerce. Le HTTPS est recommandé, car il est sécurisé (échanges chiffrés) contrairement au HTTP.
Merci à Florian Duchemin pour sa relecture !
II. Les différentes versions de HTTP
Le protocole HTTP a vu le jour en 1989, grâce aux travaux de Tim Berners-Lee et de son équipe lorsqu'il travaillait au CERN. Son idée : créer un système hypertexte sur Internet, ce qui donnera le World Wide Web et les trois fameuses lettres "www", lors de sa mise en place en 1990, avant d'être lancé officiellement auprès du grand public le 6 août 1991.
Note : dans le même temps, le langage HTML (HyperText Markup Language) a vu le jour afin de permettre la création des documents hypertextes. C'est l'un des éléments du WWW, auquel il faut ajouter le protocole HTTP bien sûr, mais aussi la gestion des URL, le client HTTP et le serveur HTTP.
Pour ces premières années d'existences du protocole HTTP, il n'y avait pas réellement de numéro de version associé, alors aujourd'hui on parle de la version HTTP/0.9. On l'appelle aussi le protocole une ligne. Pourquoi ? Tout simplement parce qu'il ne permettait que de demander une page HTML au travers d'une requête, grâce à une commande GET (nous reviendrons sur les commandes). Par exemple, la commande HTTP "GET /page1.html" renvoyait le contenu de la page HTML. Ni plus, ni moins.
C'est en 1996 que HTTP/1.0 a vu le jour quand l'IETF (Internet Engineering Task Force) en a fait une description complète au sein de la première RFC du protocole HTTP : RFC 1945. Cette version a été l'introduction de nouveaux concepts, comme les en-têtes HTTP avec le champ "Content-Type" dans le but de transférer d'autres documents que des documents au format HTML. Néanmoins, bien que basé sur le protocole TCP, le HTTP/1.0 est un protocole stateless, ce qui signifie que chaque communication entre un même client et un même serveur nécessite la création d'une nouvelle connexion.
Ensuite, en 1997 la version HTTP/1.1 a vu le jour, avant d'être révisée un peu plus tard, et elle a apportée plusieurs évolutions bienvenues comme la notion de "Keepalive" pour maintenir les connexions au-delà d'une seule requête, mais aussi, la notion de cache pour mettre en mémoire certains éléments.
En 2015, le protocole HTTP/2 a vu le jour et il est désormais utilisé sur une grande majorité de sites Internet. Néanmoins, la version HTTP/1.1 reste encore utilisée aujourd'hui. Pour l'avenir et la version HTTP/3, les choses avancent bien, même s'il n'y a pas encore de RFC correspondante.
Le HTTP/3 correspond au HTTP-over-QUIC (Quick UDP Internet Connections) et il s'appuie sur QUIC, une version améliorée de l'UDP lancée en 2012 par Google. On peut dire que QUIC est un protocole de transport qui va rentrer en concurrence avec UDP et TCP. Le HTTP/3 est déjà utilisé par certains géants de l'Internet dans le but d'avoir un Web plus rapide. Sur le site de l'IETF, le protocole HTTP/3 bénéficie désormais de sa propre RFC - après plusieurs années de travaux : IETF - RFC 9114 - HTTP/3.
Pour en savoir plus sur les différentes versions du protocole HTTP et son évolution, je vous recommande de lire cette page publiée sur le site de Mozilla : l'évolution du protocole HTTP
Voici un récapitulatif des versions du protocole HTTP :

III. Quel est le port utilisé par le HTTP ?
Pour les communications entre un client HTTP et un serveur Web, le port 80 est utilisé lorsque le protocole HTTP sert à établir la connexion. Autrement dit, le serveur Web écoute sur le port 80 pour recevoir les requêtes HTTP émises par les clients.
C'est le seul numéro de port associé au protocole HTTP. Ainsi, lorsque l'on se connecte sur une page Web, par exemple "http://www.domaine.fr", le navigateur sait qu'il doit envoyer sa requête sur le port 80 du serveur Web. Néanmoins, il est possible d'utiliser un port d'écoute différent sur son serveur Web, dans ce cas, il faudra le spécifier au niveau de la requête. Si le port 80 est remplacé par le port 8080, il faudra utiliser la syntaxe suivante : http://www.domaine.fr:8080.
Pour information, le protocole HTTPS utilise un numéro de port différent puisqu'il s'appuie sur le port 443.
Vous devez retenir que le port 80 correspond au HTTP et le port 443 correspond au HTTPS, ce qui est important lors de l'analyse de flux réseau ou la création de règles de pare-feu (filtrage des flux).
IV. Les requêtes et les réponses HTTP
Lorsqu'un client communique avec un serveur au travers du protocole HTTP, il émet une requête HTTP à destination du serveur. Autrement dit, lorsque votre ordinateur se connecte à un site Web via le protocole HTTP. Ces requêtes contiennent différentes informations, notamment des commandes HTTP et le serveur va envoyer une réponse HTTP au client.
A. Les requêtes HTTP
Commençons par les requêtes HTTP, à destination du serveur Web, émises par un client. Il est important de connaître les méthodes HTTP les plus courantes pour bien comprendre le fonctionnement du protocole HTTP. Une méthode est une commande.
Une requête HTTP contient une méthode, une cible (précisée par son chemin) et la version du protocole utilisé. En complément, la requête HTTP contient un en-tête HTTP avec différents champs qui indiquent l'hôte cible, le langage, etc...

- La méthode GET
GET est probablement la commande la plus populaire et la plus utilisée, car elle permet de demander une ressource au serveur Web. Par exemple, un fichier HTML, un fichier JavaScript ou tout simplement un fichier image. Prenons un exemple :
GET /index.html
Avec cette commande, le client, par l'intermédiaire de son navigateur Web, demande au serveur Web de lui envoyer le contenu du fichier "index.html" : nécessaire pour afficher la page d'accueil du site. En effet, le fichier "index.php" ou "index.html" fait généralement référence à la page d'accueil d'un site.
Pour une image, nous pouvons imaginer une requête comme celle-ci :
GET /images/photo1.png
Dans les deux exemples ci-dessus, nous demandons des ressources statiques au serveur Web. Néanmoins, sur un site Web dynamique, écrit en PHP, par exemple, nous pouvons ajouter des paramètres pour affiner la requête. Prenons un exemple :
GET /tutoriels.php?numero=1
Ici, nous appelons la page "tutoriels.php" en précisant le paramètre "numero" avec la valeur 1. On peut imaginer que c'est une façon de demander au serveur Web de nous fournir le contenu du tutoriel avec l'identifiant numéro 1. Quand vous accédez à une page web comme celle-ci, il y a donc de nombreuses requêtes GET effectuées pour télécharger les différentes ressources de la page.
Note : il est possible d'ajouter des caractères spéciaux dans les requêtes, en utilisant un encodage. Par exemple, le caractère "é" s'écrit "%C3%A9".
- La méthode POST
Avec la méthode GET, le contenu de la requête est visible directement dans le navigateur. Ce n'est pas idéal pour certaines informations que l'on aimerait masquer, et ce n'est pas non plus idéal pour envoyer une quantité d'informations importantes (l'URL a une limite de caractères), voire même pour charger un fichier image sur le serveur.
Heureusement, il existe une méthode plus adaptée : la commande POST. Lorsque l'on utilise la commande POST, le client n'ajoute pas les paramètres à la requête, donc ils ne sont pas visibles dans l'URL, mais ils sont ajoutés directement dans l'en-tête HTTP.
La méthode POST est très populaire pour envoyer des images et soumettre un formulaire (que ce soit une enquête en ligne ou un simple formulaire de contact). Dans le cas d'un formulaire, la méthode POST est précisée dans la déclaration du formulaire, dans le code HTML, et la page de destination s'attend aussi à réception des informations via la méthode POST.
<form action="contact.php" method="post">
- La méthode HEAD
Même si les méthodes POST et GET sont les plus populaires, vous devez savoir qu'il existe aussi la méthode HEAD. Cette méthode permet d'obtenir des informations sur la ressource en elle-même, en obtenant l'en-tête de la réponse, sans pour autant demander la ressource en elle-même. Ainsi, on peut obtenir le poids du fichier (champ "content-length" de l'en-tête) sans avoir à le télécharger réellement, par exemple.
Voici un exemple :
HEAD /images/photo1.png
A minima, vous devez connaître ces trois types de méthodes, même s'il en existe plein d'autres : OPTIONS, LOCK, UNLOCK, CONNECT, DELETE, etc.
B. Les réponses HTTP
Lorsqu'un client émet une requête HTTP à destination du serveur Web, il obtient une réponse HTTP de la part du serveur (si la requête est bien arrivée à destination). Tout d'abord, cette réponse HTTP intègre la version du protocole utilisée, mais aussi un code de retour. Ce code de retour est très important, car il indique si la requête a été traitée correctement, si elle est introuvable, ou encore si l'accès est refusé.
Comme pour la requête HTTP, la réponse HTTP intègre un en-tête particulièrement riche en informations. En effet, il peut intégrer le type de serveur Web avec le champ "Server: Apache" pour Apache (même si cela peut être supprimé en adaptant la configuration du serveur), la date, le type de contenu, la taille du contenu, le contenu en lui-même (le code source d'une page HTML, par exemple), etc.

Les codes de retour HTTP sont intéressants pour interpréter la réponse renvoyée par le serveur, et là encore, il y en a certains qui sont à connaître par cœur ! 😉
Voici la liste des codes à connaître et qui sont les plus fréquents :
- 200 : succès de la requête, donc la ressource est chargée correctement
- 301 et 302 : indique une redirection, permanente (301) ou temporaire (302), c'est utilisé lors du changement d'un domaine sur un site Web, ou lorsqu'une page change d'URL
- 403 : l'accès à la ressource est refusé par le serveur, ceci peut se produire si l'accès à une page est limité à certaines adresses IP, par exemple
- 404 : la ressource est introuvable (vous savez, la fameuse page "404 not found" ou "404 page introuvable")
- 500 : erreur côté serveur, ce qui peut être liée à une erreur de code, par exemple. Il y a aussi les codes 502 et 503, moins fréquents.
Si vous souhaitez obtenir plus d'informations sur l'ensemble des codes HTTP, vous pouvez consulter cette page : Codes HTTP.
V. Mise en pratique du protocole HTTP
Pour mettre en pratique le protocole HTTP, il est possible de mettre en place un serveur Web afin d'avoir accès au serveur et au client. Une grande majorité des serveurs Web tournent sous Linux et ils s'appuient sur Apache ou NginX. Côté Windows, la solution officielle se nomme IIS.
A. Installation d'Apache sur Debian
Si l'on prend l'exemple d'une machine Linux sous Debian, nous pouvons mettre en place un serveur Web très rapidement.
On commence par mettre à jour le cache des paquets :
sudo apt-get update
Ensuite, on installe le paquet apache2 afin d'obtenir la dernière version d'Apache 2.4.
sudo apt-get install -y apache2
Pour qu'Apache démarre automatiquement en même temps que Debian, saisissez la commande ci-dessous :
systemctl enable apache2
Dès maintenant, le serveur Web est actif et la page par défaut est accessible. Pour le vérifier, dégainez votre navigateur favori et accédez à cette adresse (en remplaçant l'adresse IP par celle de votre serveur) :
http://192.168.100.120
Voici un exemple :
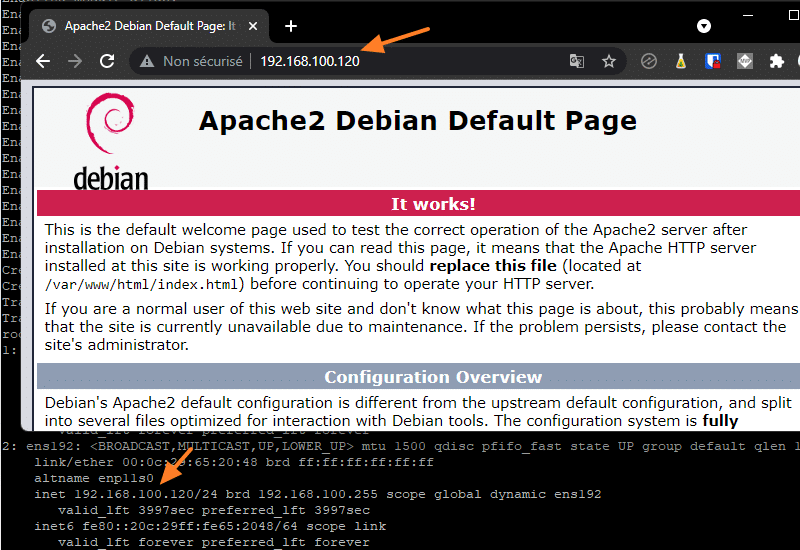
Vous allez me dire : d'où vient cette page ? En fait, Apache est livré avec un site par défaut qui est stocké à cet emplacement :
/var/www/html
La page d'index qui s'affiche quand on accède au site est située dans ce répertoire.
B. Récupérer des informations sur les en-têtes HTTP avec cURL
L'utilitaire cURL est disponible sur Windows, macOS et Linux. Il s'utilise en ligne de commande et il permet d'interroger un serveur Web afin de récupérer une ressource. Il intègre de très nombreuses options... Nous allons l'utiliser pour récupérer des informations sur les en-têtes HTTP.
Tout d'abord, si l'on indique la page cible sans préciser d'options, l'outil va exécuter la requête HTTP et afficher dans la console le code source de la page. Voici un exemple avec un serveur avec l'adresse IP 192.168.100.14 et qui dispose d'une page personnalisée :
curl http://192.168.100.14
Nous pouvons voir le code source de la page d'accueil de ce site s'afficher en retour dans la console.
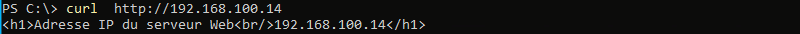
Maintenant, si l'on veut en savoir un peu plus la réponse fournie par le serveur, on peut ajouter l'option -I (ou -i pour avoir en plus le code source) :
curl -I http://192.168.100.14
On obtient ceci :

Dans l'exemple ci-dessus, je constate que la ressource s'est chargée correctement, car j'ai un code de retour "200 OK". Je constate aussi que je communique avec un serveur Apache, grâce à la mention Server: Apache (à moins que le serveur utilise une fausse valeur pour m'induire en erreur !).
Pour forcer la génération d'une erreur 404, correspondante à une page introuvable, c'est assez simple : il suffit de cibler une URL qui n'existe pas. Par exemple :
curl -I http://192.168.100.14/pageinexistante.html
Ce qui donne :
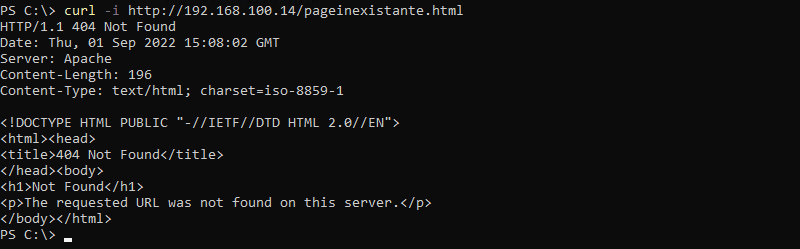
Dans l'exemple ci-dessus, nous pouvons voir le code de retour 404 Not Found qui confirme que la page n'existe pas ! Le code source de la page va dans le même sens puisque la page retournée par le serveur (il s'agit d'une page définie dans la configuration du serveur et que ce dernier doit retourner lorsqu'il y a un erreur 404) s'intitule : 404 Not Found.
Pour avoir une sortie encore plus complète, nous pouvons utiliser l'option -v qui va indiquer à la fois des informations sur la requête et sur la réponse. Voici un exemple :
curl -v http://192.168.100.14
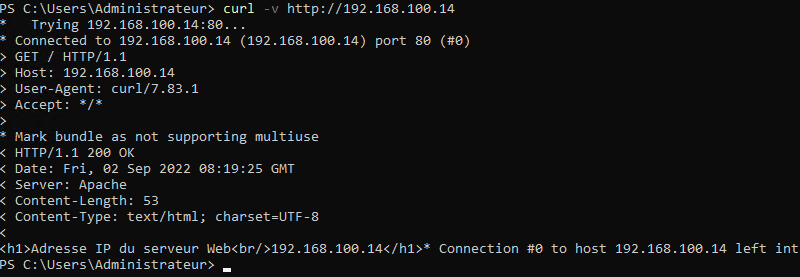
C. Analyser les flux avec Wireshark
Les informations visibles dans cURL transitent sur le réseau, entre la machine cliente et le serveur Web. De ce fait, nous pouvons capturer ces flux avec un logiciel tel que Wireshark et voir ce qui se passe d'un point de vue réseau. Sur l'image ci-dessous, je capture les flux réseau générés par la commande curl -v http://192.168.100.14. Au-delà des paquets HTTP (la requête, puis la réponse), il y a aussi des paquets TCP, car le protocole HTTP (sauf HTTP/3) s'appuie sur le protocole de transport TCP pour la gestion des connexions.
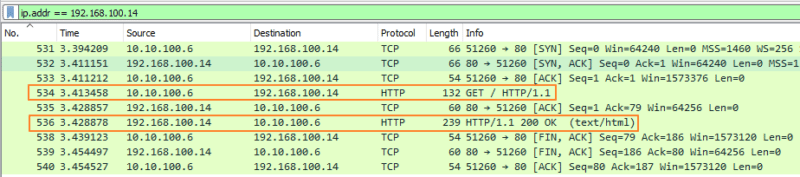
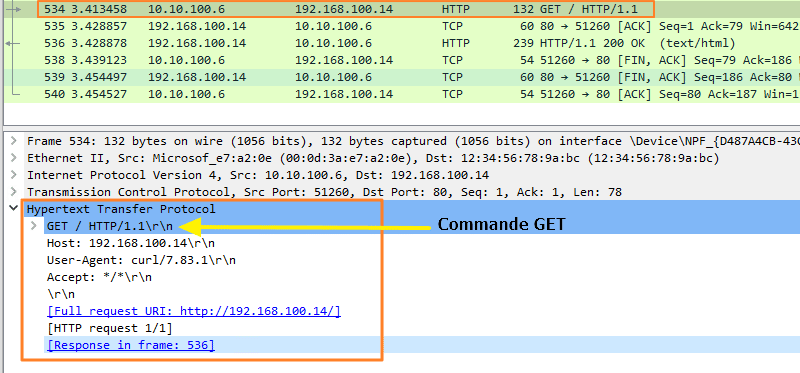
Le paquet correspondant à la requête HTTP (générée par le logiciel cURL) montre bien que la méthode GET comme commande. Puisque le protocole HTTP n'est pas sécurisé, tout le contenu de la requête est visible en clair sur le réseau.
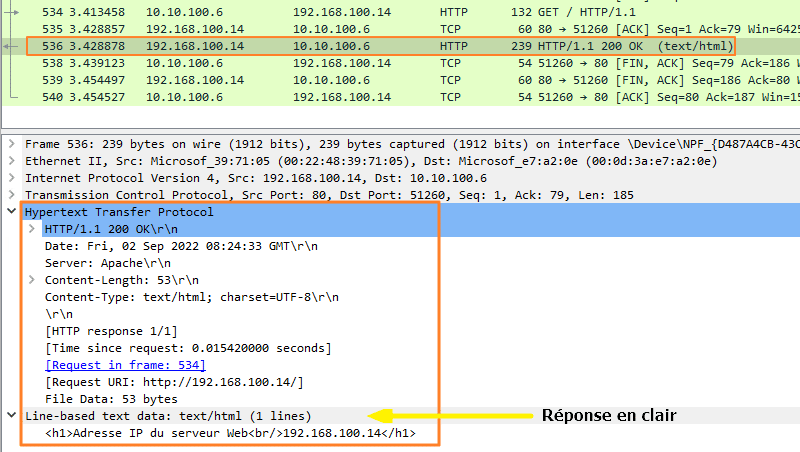
Ensuite, nous avons également le paquet correspondant à la réponse du serveur Web, avec là aussi, les informations en clair. Nous pouvons voir le code source de la page sous le champ Line-based text data.
Lorsque nous ferons le même exercice avec le protocole HTTPS, nous verrons que les flux sont chiffrés et qu'une capture réseau ne permet pas d'obtenir toutes ces informations.
C'est également vrai avec le protocole HTTP/3 qui s'appuie sur le protocole de transport QUIC à la place de TCP, et qui intègre nativement du chiffrement. En effet, QUIC est un nouveau protocole de transport qui bénéficie du chiffrement natif (pas de version en clair), ce qui permet d'utiliser le protocole HTTP tout en bénéficiant du chiffrement. QUIC est un protocole d'avenir, déjà utilisé par les géants du Web (et pris en charge dans certains navigateurs). Il devrait faire parler de lui dans les prochaines années : c'est un protocole optimisé pour le Web, mais qui pourrait être utilisé pour d'autres usages.
D. Ressources supplémentaires
Voici quelques tutoriels complémentaires sur la mise en œuvre d'Apache, Nginx et IIS :
- Installer un serveur LAMP (Linux Apache MariaDB PHP) sous Debian 11
- Installer un serveur Web LAMP (Apache, MySQL, PHP) sur WSL 2
- Debian – comment installer Nginx en tant que serveur Web ?
- Installer et configurer IIS 10 sur Windows Server 2022
- Comment installer IIS sur Windows 11 ?
VI. Conclusion
Cette introduction au protocole HTTP touche à sa fin, désormais, vous en savez plus sur l'histoire de ce protocole, son fonctionnement et vous êtes en mesure d'interpréter un minimum les requêtes et les réponses HTTP. Dans un prochain article, nous étudierons le protocole HTTPS, mais il me semblait important de s'intéresser au protocole HTTP dans un premier temps puisque HTTPS est une évolution qui améliore la sécurité.
Qu'en pensez-vous ?










