

Forensic – SteerOnSomewhere : analyse de PDF et EXE malveillants
Sommaire
I. Présentation
Nous continuons notre suite d'articles sur le CTF du FIC 2021 proposé par l'école EPITA afin de découvrir certains outils et méthodes de forensic (investigation numérique). Dans cet article nous allons nous pencher sur l'analyse de fichiers PDF et exécutables contenant des objets ou du code malveillant.
Cette enquête est découpée en 5 articles, voici la liste des articles :
- Cas n°1 : PhishingBoat - analyse d'un fichier Mbox et d'un fichier PDF malveillant
- Cas n°2 : FloatingCredentials - analyse d’une capture WireShark
- Cas n°3 : EngineX - détection d'un scan nmap et analyse réseau d'un protocole propriétaire industriel
- Cas n°4 : SteerOnSomewhere - analyse de PDF et EXE malveillants
- Cas n°5 - PearlArmor : analyse de journaux et d'une image disque
II. Contexte : Panic on board - SteerOnSomewhere
Le contexte de l'incident sur lequel nous intervenons est le suivant : Un bateau de croisière de la compagnie maritime ArMor a subi une panne et se retrouve bloqué en pleine mer.
Nous savons à présent qu'à la suite d'un phishing, l'attaquant est parvenu à dérober les identifiants VPN d'un utilisateur puis à mener une attaque sur les automates du bateau afin de les arrêter. Le contexte de cette quatrième étape de l'analyse est le suivant :
L’analyse du logiciel d’IHM (auquel seul le technicien a accès) n’a rien révélé de probant. Sur le point d’abandonner, vous tombez sur quelques fichiers de documentation anodins… Ou pas ? Découvrez comment les ordres d’arrêter les machines ont été donnés.
Deux fichiers nous sont ici fournis :
- s7-300_IHB_f.pdf
- stopAutomatesProp.exe
Nous devons répondre aux questions suivantes pour compléter cette quatrième étape de l'analyse :
- Le fichier PDF cache du contenu ;
- La fonction de décodage utilisée pour désobfusquer la charge utile ;
- La charge utile est... ;
- Vous avez extrait le fichier embarqué. En quel langage le programme est-il écrit ;
- Le temps en secondes que le script passe à dormir.
N'oublions pas de vérifier l'intégrité des éléments récupérés (le hash BLAKE2 est fourni avec les fichiers sur le site du challenge) :
$ b2sum s7-300_IHB_f.pdf
f5d2ef2e841e24731187d310677312c2a78d58b540eeabff69832625a508fc84f8147c7891eafedfbc76fc99ae880c4dc3858280bf28b4fa512d75c2bbcaf5f2 s7-300_IHB_f.pdf
$ b2sum stopAutomatesProp.exe
30ff3011c25368fa1d4e09632874c0781199aa62d4ad57b47a99ae39bff6480fff2639a70dbe498f93b6aa263cf86d49a5f66a2d7bf3cdfc38f3f15903e22186 stopAutomatesProp.exe
Vous trouverez le challenge en question et les fichiers utilisés dans cet article ici : Panic On Board - SteerOnSomewhere
III. Analyse d'un PDF
Comme je l'ai indiqué dans l'article Forensic – PhishingBoat : analyse de fichiers Mbox et PDF, les fichiers PDF peuvent être utilisés de façon malveillante afin de transporter d'autres objets, parfois chiffrés ou encodés, et déclencher des actions à leur ouverture. Pour décortiquer ce fichier PDF, nous allons commencer par utiliser le script pdfid.py de Dider Stevens :
$ pdfid.py s7-300_IHB_f.pdf
PDFiD 0.2.1 s7-300_IHB_f.pdf
PDF Header: %PDF-1.4
obj 3253
endobj 3253
stream 295
endstream 295
xref 3
trailer 3
startxref 3
/Page 245
/Encrypt 0
/ObjStm 0
/JS 1
/JavaScript 1
/AA 1
/OpenAction 2
/AcroForm 0
/JBIG2Decode 0
/RichMedia 0
/Launch 1
/EmbeddedFile 0
/XFA 0
/Colors > 2^24 0
pdfid.py n'est pas un parser PDF, mais il analysera un PDF pour rechercher certains mots-clés permettant d'identifier les documents PDF contenant (par exemple) du JavaScript ou d'exécuter une action lorsqu'ils sont ouverts.
Ici, celui-ci nous indique que le fichier fait 245 pages et contient du code Javascript (/JS, /Javascript) ainsi que des éléments permettant l'exécution d'instructions à l'ouverture (/AA, /OpenAction, /Launch). Nous pouvons compléter notre analyse avec l'utilisation de l'outil pdfdetach, qui vient de la suite d'outil origami :
$ pdfdetach s7-300_IHB_f.pdf -list
Syntax Warning: Illegal URI-type link
Syntax Warning: Illegal URI-type link
1 embedded files
1: s7-300_IHB_f.pdf
Contrairement à pdfid.py, pdfdetach détecte un fichier embarqué dans le PDF, tentons d'en savoir plus avec pdf-parser et utilisons l'option --search, qui permet d'effectuer un filtre sur un mot précis :
$ pdf-parser.py --search embedded s7-300_IHB_f.pdf
obj 3246 0
Type:
Referencing: 3247 0 R
<<
/EmbeddedFiles 3247 0 R
>>
Un PDF est composé de multiples objets de différents types qui sont numérotés de façon unique et référencés dans la XREF table (cross reference table). Ici, nous voyons que l'objet 3246 0 référence l'objet 3247 0 en tant que fichier embarqué, nous pouvons ici utiliser l'option --object pour afficher directement le contenu de cet objet :
$ pdf-parser.py s7-300_IHB_f.pdf --object 3247
obj 3247 0
Type:
Referencing: 3248 0 R
$ pdf-parser.py s7-300_IHB_f.pdf --object 3248
obj 3248 0
Type: /Filespec
Referencing: 3249 0 R
Nous arrivons enfin à l'objet 3249 0 pour lequel nous devons ajouter les options --filter et --raw pour avoir une sortie brute de son contenu. Celui-ci étant un stream, pdf-parser n'affiche pas son contenu par défaut (un stream peut être très volumineux) :
$ pdf-parser.py s7-300_IHB_f.pdf --object 3249 --filter --raw
obj 3249 0
Type:
Referencing:
Contains stream
b'MZ\x90\x00[...]
Dans un fichier PDF, les streams sont des séquences d'octets qui peuvent être de longueur illimitée et peuvent être compressés ou encodés. En tant que tels, ils constituent le type d'objet utilisé pour stocker de gros blocs de données (blob) qui sont dans un autre format standardisé, (XML , image, police, etc.).
Et justement, nous voyons ici le début du contenu du blob dans ce stream et il commence par MZ, il s'agit du magic byte caractéristique des fichiers exécutables Windows.
Les magic bytes, ou signatures de fichier, sont simplement les premiers octets composant un fichier et indiquant son format, on peut les considérer comme un "en-tête" qui va ensuite indiquer au système quels programmes peuvent les ouvrir, puis aux programmes comment ils sont composés (un peu à l'image d'un paquet pour Wireshark et ses dissecteurs). Ainsi un fichier PNG commencera toujours par 89 50 4E 47 0D 0A 1A 0A, un fichier PDF par 25 50 44 46 2D et un fichier exécutable par 4D 5A, soit MZ en conversion ASCII.
C'est notamment sur ces éléments que se basent les outils de File Carving ou de récupération de fichiers supprimés qui permettent de trouver les fichiers contenus dans un autre fichier ou un espace disque donné (image disque, firmware, PDF, etc.). On peut notamment citer foremost, binwalk, bulk_extractor, etc. Voici une liste des magics bytes par format de fichier : List of file signatures
Nous pouvons donc affirmer ici que notre fichier PDF embarque un fichier exécutable Windows, ce qui est des plus suspect. Nous pouvons ici citer la T1204.002 User Execution: Malicious File du MITRE ATT&CK.
Nous pouvons également utiliser l'outil PeePDF pour avoir une synthèse des informations sur cet objet spécifique :
PPDF> info 3249
Offset: 3608903
Size: 7423903
MD5: 8057276523631af3456969a2372971f9
Object: stream
Subtype: /application/pdf
Stream MD5: c53391adcd8cb8b2ad4995c78c13aca7
Raw Stream MD5: acbe518d8f95f884467b4c42cea1598c
Length: 7423727
Encoded: Yes
Filters: /FlateDecode
Filter Parameters: No
Decoding errors: No
References: []
Nous voyons ici une notion importante lors de l'analyse d'objet dans un PDF : Filters: /FlateDecode. Dans un PDF, les Filters sont le moyen utilisé pour encoder un objet. Le fait d'indiquer en clair ce Filter permet ensuite aux lecteurs PDF de les décoder facilement. Cela nous permet de répondre à la question suivante :
- La fonction de décodage utilisée pour désobfusquer la charge utile : FlateDecode
- La charge utile est... : PE Executable
Je note au passage qu'il existe une multitude d'outils pour analyser un PDF, certains très anciens (avant 2010) qui fonctionnent encore et d'autres plus récents. Lorsque l'on aborde ce domaine, il n'est pas évident de s'orienter sur un outil spécifique (aucun ne semble contenir à lui seul toutes les fonctions utiles) ou au contraire de jongler entre les différents outils (commandes, syntaxes et sorties différentes à chaque fois). PeePDF me parait cependant assez dynamique, l'analyse interactive apparait comme un plus, par exemple pour suivre les objets qui se référencent entre eux. Voici la synthèse des outils utilisés dans cet article :
- pdfid.py de Didier Stevens;
- pdf-parser.py de Didier Stevens;
- la commande pdfdetach de la suite origami;
- peepdf.
L'ANSSI a également sorti un outil d'analyse de PDF qui ne semble plus maintenu aujourd'hui et que je n'ai pas du tout réussi à installer 🙁 : Caradoc.
IV. Analyse basique d'un exécutable
Un binaire, ou exécutable, peut être étudié de différentes façons, souvent complémentaires :
- l'analyse statique : elle consiste à récupérer certains éléments tels que les hashs (empreinte numérique et unique du fichier), l'analyse antivirus, l'analyse d'un dump mémoire, la détection des packers, etc. Ce fichier binaire peut ensuite faire l'objet d'un reverse engineering à l'aide d'un désassembleur pour convertir le code machine en code assembleur afin de le rendre "lisible" par l'homme.
- l'analyse dynamique : elle consiste à analyser le comportement des binaires malveillants dans un environnement sandbox (bac à sable) afin qu'ils n'affectent pas les autres systèmes. Différentes "sondes", métriques et autres éléments de détection et de surveillance sont alors utilisés pour capturer et analyser le comportement du malware à son exécution (fichiers ouverts, connexion réseau, API systèmes utilisées, etc.)
Lors de la réalisation d'une analyse statique de base, nous n'exécutons pas directement le code du binaire malveillant analysé ni n'ouvrons de désassembleur pour tenter de disséquer ce binaire. La première étape est d'obtenir un aperçu rapide de la structure de l'exécutable et d'identifier les premiers éléments d'analyse. Commençons par un simple strings sur le binaire fourni dans le cadre du challenge :
strings stopAutomatesProp.exe
bpython38.dll
bselect.pyd
bstopAutomatesProp.exe.manifest
bucrtbase.dll
bunicodedata.pyd
opyi-windows-manifest-filename stopAutomatesProp.exe.manifest
xInclude\pyconfig.h
xbase_library.zip
zPYZ-00.pyz
&python38.dll
La commande Linux strings est utilisée pour détecter et afficher les chaines de caractères présentes dans des fichiers. Elle se concentre principalement sur la détermination du contenu et l'extraction du texte des fichiers binaires (fichier non texte).
On retrouve ici plusieurs lignes contenant le mot python ou python38. Il s'agirait donc d'un exécutable contenant du Python. Ce qui est inhabituel, c'est que l'on ne produit habituellement pas de .exe en Python étant donné qu'il s'agit d'un langage interprété et non compilé. Il existe néanmoins une solution permettant de faire cela : Transformer un script Python en exécutable avec PyInstaller
Après quelques recherches, je remarque qu'il est possible de faire l'opération inverse lorsque l'on a sous la main un exécutable produit via Python : https://github.com/extremecoders-re/pyinstxtractor
$ python3.8 pyinstxtractor.py ../stopAutomatesProp.exe
[+] Processing ../stopAutomatesProp.exe
[+] Pyinstaller version: 2.1+
[+] Python version: 38
[+] Length of package: 7298295 bytes
[+] Found 71 files in CArchive
[+] Beginning extraction...please standby
[+] Possible entry point: pyiboot01_bootstrap.pyc
[+] Possible entry point: pyi_rth_multiprocessing.pyc
[+] Possible entry point: pyi_rth_pkgres.pyc
[+] Possible entry point: stopAutomatesProp.pyc
[+] Found 254 files in PYZ archive
[+] Successfully extracted pyinstaller archive: ../stopAutomatesProp.exe
You can now use a python decompiler on the pyc files within the extracted directory
PyInstaller Extractor est un script Python permettant d'extraire le contenu d'un fichier exécutable Windows généré par PyInstaller. Le contenu du fichier (généralement des fichiers .pyc) est présent dans l'exécutable est également extrait. Et oui, lorsque PyInstaller génère l'exécutable à partir du code python, celui-ci positionne le bytecode dans l'exécutable, ce qui facilite sa récupération. Vous trouverez plus d'informations sur le fonctionnement de PyInstaller ici : What PyInstaller Does and How It Does It
Nous nous retrouvons donc avec un ensemble de fichiers .dll et .pyc (entre autres) :
Les fichiers .pyc sont des fichiers Python compilés. Mais si Python est un langage interprété, pourquoi existe-t-il des formats de fichiers compilés ?
Les fichiers .pyc sont une version pré-compilée du code d'un fichier .py (script en texte clair). Il s'y trouve un code en format bytecode, ce qui permet de gagner du temps lors de l'exécution, car le système n'aura pas à faire lui-même cette conversion. Lorsque l'on dispose du fichier .pyc, le code en clair (fichier .py) n'est plus nécessaire à l'exécution.
Le format de fichier .pyc est donc du bytecode, il s'agit d'un format de code intermédiaire entre les instructions-machine et le code source, qui n'est pas directement exécutable. Il ne s'agit pas d'une mesure d'obfuscation et l'opération inverse (bytecode vers code source) peut elle aussi être réalisée, à l'aide de uncompyle6 notamment :
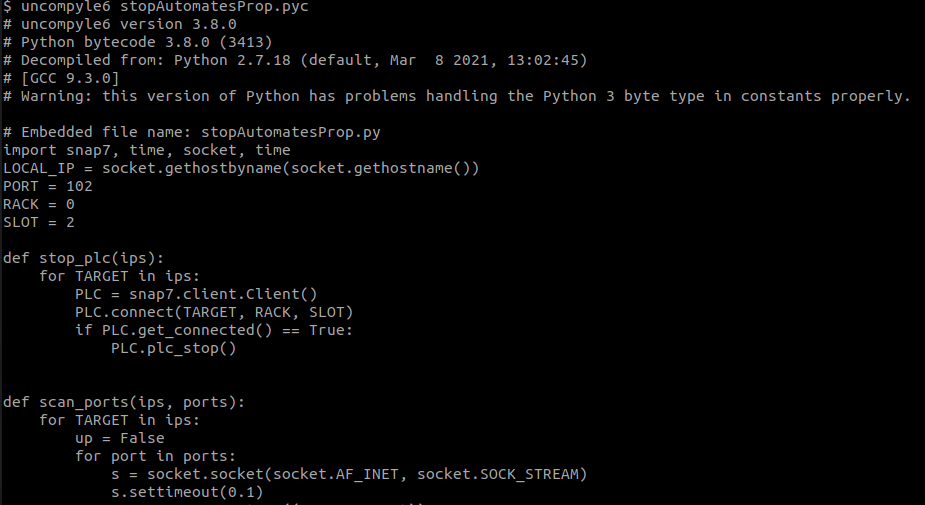
Nous récupérons ici le code source en clair de notre exécutable malveillant, ce qui est bien plus simple à étudier qu'une analyse en assembleur :). On remarque notamment une fonction stop_plc et une fonction scan_port, ce qui correspond aux éléments observés lors des précédentes étapes de notre analyse. En fin de script, on remarque la fonction suivante :
else:
time.sleep(36000)
scan_ports(available_ips, [80, 445, 443, 25, 110, 139, 23, 21, 3389, 22, 102])
time.sleep(1231)
stop_plc(available_ips)
Notre script fait 2 pauses à l'aide de l'instruction time.sleep. Il s'agit d'un comportement visant à espacer les scans de port et les actions d’arrêt du PLC dans le temps, notamment afin de tromper des systèmes de détection (IPS, sondes de détection, antivirus) qui pourraient baser leur analyse sur le nombre d’occurrences d'un évènement dans le temps.
Cela nous permet de répondre aux dernières questions de notre analyse :
- Vous avez extrait le fichier embarqué. En quel langage le programme est-il écrit : Python
- Le temps en secondes que le script passe à dormir : 37231
Lorsqu'un antivirus exécute un programme en sandbox (bac à sable) avant de le considérer comme sûr, celui-ci ne peut se permettre de faire durer son analyse plusieurs minutes (ce serait désagréable pour l'utilisateur), il est donc courant qu'un programme malveillant profite de ce comportement afin de n'exécuter son action malveillante qu'après un temps d'attente. L'antivirus n'ayant pas la patience d'attendre ce temps va souvent arrêter son analyse au bout d'un certain temps et ne jamais exécuter le code malveillant, qui ne sera alors pas détecté. Cette mesure est décrite dans la T1497.003 Virtualization/Sandbox Evasion: Time Based Evasion du MITRE ATT&CK.
Nous avons vu dans cet article qu'un PDF peut cacher bien des choses et notamment un exécutable Windows. Différents outils ont été utilisés ici, mais nous sommes loin de l'exhaustivité. Nous sommes tout de même parvenus à retrouver, via le code source, l'exécutable responsable des activités identifiées au niveau des traces réseau dans les articles précédents. Cela nous donne donc un bon aperçu de comment quelques lignes de code peuvent avoir un impact très important sur un système d'information.
Le prochain article, et dernier de cette série sur le scénario de l'attaque du SI d'un navire, portera sur l'analyse de journaux d'évènements, de fichiers supprimés, d'une image OVA et d'une image disque :).










