

Dirhunt – Enumération des répertoires web sans brute force
Sommaire
I. Présentation
Je vous présente dans ce court article un outil que j'ai découvert récemment lors de la résolution des challenges natas. Il s'agit de dirhunt, un outil d’énumération de répertoires web qui n'utilise pas la technique du bruteforce.
Les méthodes les plus communes pour lister avec le plus d'exhaustivité possible les répertoires d'une application web sont les deux suivantes :
- Utiliser un proxy web (BurpSuite, OWASP ZAP), positionné entre notre navigateur et le serveur web, et utiliser manuellement l'application web avec le plus d’exhaustivité possible. On essai d'accéder à toutes les pages, tous les formulaires, etc. On se retrouve au final avec un grand nombre de fichiers et répertoires listés dans notre proxy.
- Utiliser un dictionnaire (aussi appelé wordlist) contenant un ensemble de noms de répertoires "communs", c'est à dire qui sont très souvent présents sur les applications web. Par exemple https://monsite.fr/blog, /contact, /image, /css etc. Plus nous avons de temps et une wordlist complète, plus nous aurons de chance de trouver un grand nombre de répertoires. Des outils tels que dirbuster ou dirsearch permettent de réaliser ce type d'opération.
Ces deux méthodes sont généralement efficaces mais peuvent montrer quelques limites. Pour la méthode du proxy, le temps d'obtention d'une liste complète des répertoires dépend de la taille de l'application web. L'opération peut être longue à réaliser car la découverte se fait surtout manuellement. Pour la méthode de l'énumération, cela est aussi assez long et beaucoup de requêtes sont envoyées pour rien (si 10% du contenu de votre dictionnaire retourne des résultats positifs, vous serez déjà très chanceux). Un très grand pourcentage du trafic (et du temps) généré sera donc inutile.
Dirhunt peut ici être utilisé pour compléter ces deux méthodes. Il agit comme un crawler, c'est à dire qu'il va suivre tous les liens des pages web du site ciblé, et cela automatiquement.
Un robot d'indexation (ou littéralement araignée du Web ; en anglais web crawler ou web spider) est un logiciel qui explore automatiquement le Web. Il est généralement conçu pour collecter les ressources (pages Web, images, vidéos, documents Word, PDF ou PostScript, etc.), afin de permettre à un moteur de recherche de les indexer.
A chaque nouvelle page analysée, il recherche dans le code source de ces pages les répertoires et met à jour une liste de répertoires valides sur l'application web au fur et à mesure.
II. Enumération des répertoire web, pour quoi faire ?
Avant de passer à la démonstration et aux options et cas d'utilisation de dirhunt, discutons un peu des contextes dans lesquels une énumération des répertoires web peut être utile.
Lors de l'analyse de la sécurité d'une application web (incluons là dedans bug bounty, audit de sécurité, etc.) la cartographie est l'une des première étape à mener. Plus la cartographie est complète, moins nous aurons de chance de passer à côté d'une fonction, d'un formulaire ou d'une page contenant des vulnérabilités. La cartographie sert en somme dessiner le périmètre de l'application.
Dans un tel contexte, on énumère notamment les sections du site web (une partie authentifiée, une partie en accès non authentifié), sa technologie (via le banner grabbing et autres indicateurs), ses fichiers et ses répertoires.
Quoi de plus facile de commencer l'analyse de la sécurité d'une application web en tombant dés les premières minutes sur un répertoire /backup contenant une archive ZIP avec le contenu de la base de donnée ?
L'énumération des répertoires (et fichiers) d'une application web et donc une étape essentielle à exécuter durant les phases de reconnaissance d'une application, potentiellement à réitérer plus tard, par exemple un fois que l'on a obtenu un accès authentifié.
III. Installation et utilisation de dirhunt
Dirhunt est écrit en Python et est disponible sur Github (https://github.com/Nekmo/dirhunt), il peut également être installé depuis pip3 :
pip3 install dirhunt
Rien de plus compliqué que cela, il suffit ensuite de l'utiliser. Une documentation plutôt complète est disponible sur le blog de l'auteur : http://docs.nekmo.org/dirhunt/usage.html
Pour exposer quelques cas d'utilisation, le plus simple est le suivant :
dirhunt https://ogma-sec.fr
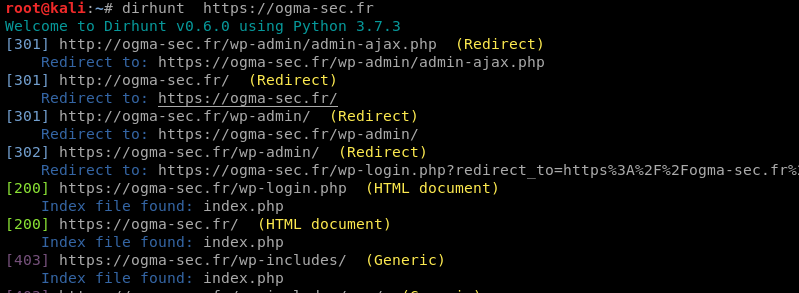
On peut également spécifier plusieurs cibles :
dirhunt https://ogma-sec.fr/rep1 https://wikipedia.org
L'option la plus intéressante est la possibilité de filtrer par liste blanche ou liste noire les résultats. Cela permet d'exclure les redirections, les erreurs 404 ou au contraire de n'afficher que les Directory Listing (qui sont relevés et indiqués par dirhunt) :
dirhunt https://ogma-sec.fr/ --include-flags "Index Of" dirhunt https://ogma-sec.fr/ --exclude-flags "404"
Dirhunt se base donc sur la méthode des crawlers des moteurs de recherche. En théorie, il est également censé aller chercher des informations sur Google, VirusTotal, ou encore le fichier robots.txt (si présent), mais après avoir testé l'outil, il semble que cette partie fonctionne mal, j'ai levé une issue sur son Github.
Enfin pour stocker tous les répertoires trouvés dans un fichier, on utilise le classique chevron :
dirhunt https://ogma-sec.fr > dir-ogma-sec.fr
J'ai pour ma part essayé de développer mon propre outil avant de trouver celui-ci, notamment pour résoudre le challenge Natas 4 (article à venir). La tâche n'est pas facile car il faut prévoir tous les cas possibles, redirection, 404, 403, savoir reconnaitre quand une URL contient plusieurs répertoires, pouvoir prendre en entrée plusieurs types de données, des fichiers externes (possible avec dirhunt en indiquant un /chemin/fichier à la plage de l'URL en entrée), etc.
Bref, un outil très utile, il lui manque peut être la gestion de l'authentification en option. Le code étant en Python, il peut être facilement modifié si nécessaire.










