Backupez vos données avec Back In Time
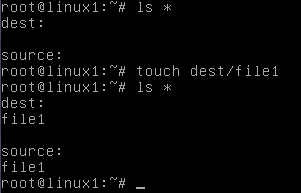
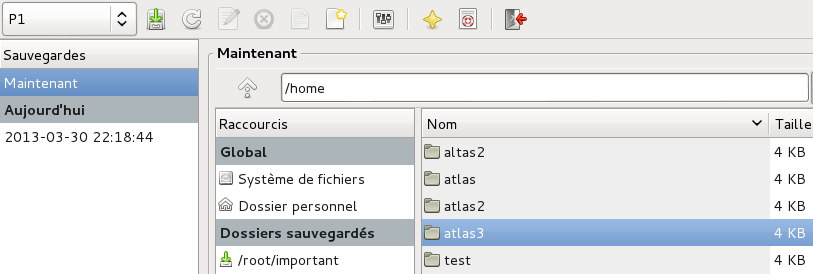
I. Présentation Back in Time est un petit outil disponible sur les distributions Debian Linux qui permet de backuper de façon automatique les données d’un poste et cela de façon trés simple. Il faut savoir que Back In Time fonctionne actuellement sur deux bureaux : Gnome et KDE. II. Installation Nous allons commencer par installer l’outil de 35Mo qui nous fournira une interface graphique afin de configurer nos backups. On ouvre pour cela un terminal avec les droits administrateur et on saisi la commande suivante : apt-get update && apt-get install backintime-gnome Note: Le tutoriel est ici fait sur un bureau GNOME mais pour KDE, la commande sera la suivante : apt-get update && apt-get install backinttime-kde4 On trouvera ensuite notre outil « Back in Time » dans la partie « Outils système » : Dans le cadre du tutoriel et pour éviter de se faire embêter, nous allons ici le lancer ne root mais la gestion particulière des droits peut certainement vous amener
Lire cet article