

Pile processus & mémoire : schedtool, powertop, pidstat, vmstat, etc.
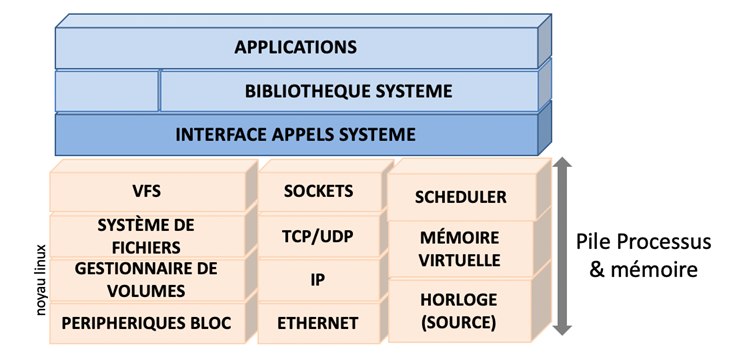
A ce niveau, on va traiter de la problématique des processus et tout particulièrement de leur empilement et leur ordonnancement les uns avec les autres. Cela revient à se demander comment ses éléments sont répartis au sein de la mémoire. Cette nouvelle se décompose en trois briques principales :
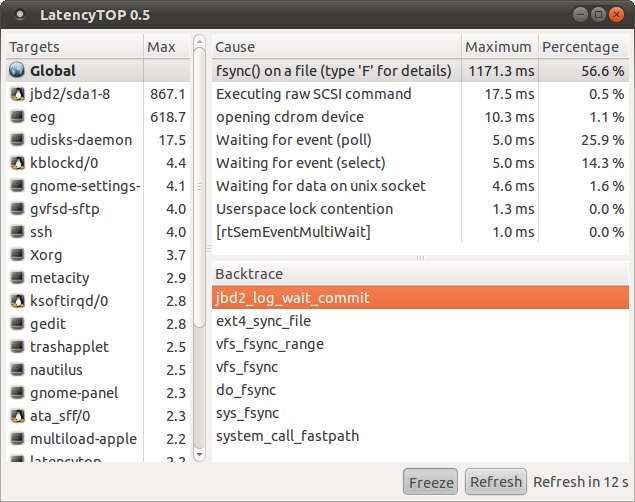
En ce qui concerne la couche de l’ordonnanceur du système, il existe de nombreux outils permettant de fournir les statistiques, d’autant que les axes d’interrogation sont aussi divers que variés. Par exemple, si l’on veut connaître l’élément provoquant certaines latences, il faut interroger le système à l’aide de la commande latencytop. Cet outil, propre aux développeurs, affiche alors le type d’opération ou d’action provoquant des délais d’attente. On récupère par la même occasion la section du système en cause.
La commande affiche alors un pseudo-terminal dans lequel on retrouve les différents processus exécutés, leur temps d’exécution et la répartition de ce temps de traitement :
En termes d’ordonnancement (on parle aussi de scheduling), on peut alors compter sur l’utilitaire schedtool permettant de modifier ou d’afficher les politiques de gestion d’ordonnancement des processeurs ou CPU. Cela peut notamment permettre de verrouiller certaines tâches sur tel ou tel processeur au niveau des systèmes SMP ou NUMA, favorisant ainsi des résultats constants lors de benchmark ou de communication réseau, en ajustant l’exécution de celles-ci avec des mécanismes de type (re)nice sur les processus. Le formalisme d’appel est le suivant :
# schedtool -<Mode> <ListPID>
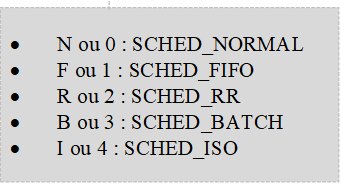
Exemple : lister les traitements de type “batch“ :
# schedtool -B <PID>
On peut aussi faire en sorte d’élever la priorité d’un processus via la commande nice grâce à la commande schedtool :
# schedtool -n 10 <PID>
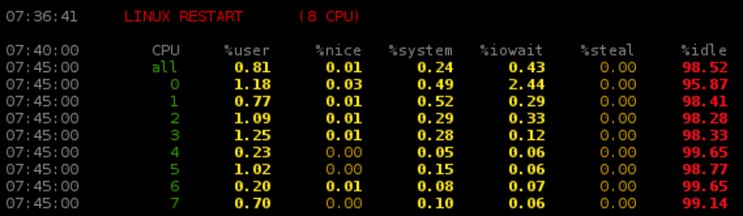
Si l’on souhaite connaître l’activité courante de chacun des processeurs présents sur notre machine, on peut alors compter sur la commande mpstat qui, nativement affiche les informations pour l’ensemble des processeurs actifs du système :
# mpstat
REMARQUE : on peut également utiliser la commande sysstat qui permet également d’afficher les informations d’activité des différents processeurs du serveur.
Un autre aspect de la consommation des ressources sur un serveur concerne plus spécifiquement l’alimentation électrique. Pour cela, on peut se servir de la commande powertop. Il s’agit en réalité d’une application pour le terminal sans interface graphique, développée par Intel, permettant de contrôler et réguler la consommation énergétique des portables, fonctionnant sur batterie :
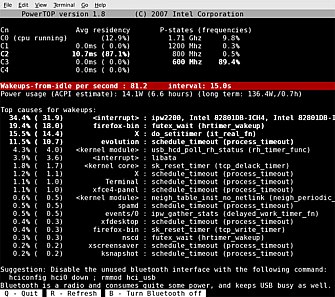
Cet outil, comme on peut le constater, affiche une vue d’ensemble de la consommation des applications et des périphériques du système, tout en listant les statistiques d’utilisation des différents processeurs.
ATTENTION : afin de pouvoir utiliser ce logiciel, il faut impérativement disposer d’un processeur Intel et d’un noyau minimum en 2.6.21. Il faut par ailleurs, se trouver sur un portable fonctionnant sur batterie.
Si l’on souhaite appliquer les recommandations fournies par le logiciel, on peut alors exécuter la commande suivante :
# powertop --auto-tune
On trouve également des informations d’entrées/sorties et de consommation mémoire, au travers des différentes commandes top, htop ou encore iotop, déjà mentionnée ultérieurement.
Si l’on souhaite disposer d’une liste de processus et de leur consommation lors de leur exécution, il suffit d’utiliser la commande ps et ses nombreuses options d’affichage. Enfin, lorsqu’on s’intéresse à un processus en particulier, il n’existe aucune autre commande mieux adaptée que pidstat.
Exemple : lister les processus Ansible en cours d’exécution :
# pidstat -C "ansible"
De la même façon, pour lister les caractéristiques d’un processus en particulier, il suffit d’exécuter la commande ci-dessous :
# pidstat -p 3203 Linux 3.0.101-0.7.17-default (mylinux) 01/30/20 _x86_64_ 05:04:29 PID %usr %system %guest %CPU CPU Command 05:04:29 3203 0.00 0.00 0.00 0.00 0 vim
RAPPEL : bien évidemment, en termes d’information concernant les processus, on peut également scruter le contenu des différents fichiers se trouvant dans l’arborescence /proc/stat.
Il est possible d’utiliser aussi la commande système sar ainsi que des audits mis en place au niveau de la machine lors de son initialisation, afin de récupérer de l’information en continu sur le système et son activité :
# sar
Généralement, des audits sont déjà activés sous forme de tâches planifiées, au sein de la crontab du compte sysstat :
*/2 * * * * root /usr/lib64/sa/sa 1 1 1
Lors des opérations de configuration et de débogage, on peut être amenés à utiliser plusieurs commandes simultanément : free, vmstat, iotop, iftop… Il existe cependant un utilitaire permettant de centraliser l’information ainsi récoltée : dstat. Par défaut, si aucune métrique n’est utilisée, dstat affiche les colonnes cpu (lettre c), disque (lettre d), réseau (lettre n), pagin (lettre g) et système (lettre y). Pour n’afficher qu’une de ces colonnes, il suffit de le mentionner via les options utilisées :
# dstat -dn
REMARQUE : il est possible de préciser que l’on attend une sortie vers un fichier de sortie EXCEL. De plus, certaines options permettent de visualiser le ou les processus ayant consommé le plus de ressources disque et/ou mémoire via les options --top-io ou --top-mem.
De plus, à ce niveau, on dispose également des fonctions eBPF permettant de s’intéresser précisément aux informations propres aux processus en cours d’exécution et aux processeurs sur lesquels ces tâches s’exécutent :
- cpudist
- execsnoop
- runlat
- offcputime
Dans le cas de cette dernière commande, il est possible de relever tous les événements bloquants en termes de threads :
# offcputime
Au niveau de la couche de mémoire virtuelle, là encore on retrouve de nombreux outils, souvent utilisés également au niveau de la couche de l’ordonnanceur. Il s’agit des commandes telles que top, htop, ps, sar ou encore pidstat.
De façon plus précise, en considérant l’aspect spécifique de l’utilisation de la mémoire, on peut également évoquer la commande free, permettant d’afficher la répartition de son utilisation selon les différentes catégories de mémoires et de tampons :
# free
REMARQUE : il existe également la commande uptime qui affiche la moyenne d’utilisation de la mémoire :
# uptime 08:11:22 up 146 days, 34 min, 3 users, load average: 0.28, 0.45, 0.38
On trouve également un utilitaire très pratique permettant d’afficher la consommation de la mémoire et la répartition sur les différents processus actifs : vmstat. L’avantage de cette commande est qu’elle permet de générer des rapports concernant les statistiques de la mémoire virtuelle, ainsi que les informations des différents évènements système :
- charge CPU,
- pagination,
- changement de contexte,
- interruption de périphériques
- appels système
RAPPEL : en paramètre de la commande vmstat, il est possible de passer un intervalle suivi du nombre d’itérations à exécuter.
Exemple : effectuer un relevé toutes les 3s en itérant 30 fois :
# vmstat 3 30
On peut ainsi facilement collecter périodiquement, sous forme de tâche de fond, des mesures en redirigeant les données vers un fichier estampillé en sortie :
#!/bin/bash DATE=`date +"%Y-%m-%d"`​ if [ ! –d /var/log/vmstat ] ; then mkdir /var/log/vmstat ; fi /usr/bin/vmstat $1 $2 > /var/log/vmstat/vmstat.$DATE
Ce script peut être planifié sous forme de tâche crontab tous les soirs à 23h00, ou tout autre horaire susceptible de convenir et ne pas gêner l’activité nocturne des serveurs. L’activité de la mémoire virtuelle et sa répartition peuvent également être consultée en éditant le contenu du fichier /proc/meminfo.
On ne sera pas surpris non plus de savoir qu’à ce niveau on retrouve une fois de plus des fonctionnalités eBPF permettant de tracer les événements survenus en mémoire sur un serveur :
- slabtop
- slabratetop
- memleak
Si l’on s’intéresse aux informations orientées temporisation et estampillage, on peut alors interroger le système à l’aide d’une des commandes ci-dessous :
- ntpq
- chronyc
La première commande fait référence au protocole NTP, configurable depuis le fichier /etc/ntp.conf et la seconde est apparentée au service chronyd. Pour visualiser les informations de synchronisation temporelle, il suffit d’exécuter la commande suivante :
# chronyc tracking
REMARQUE : avec le protocole NTP, la commande à utiliser pour disposer des informations de synchronisation est plutôt :
# ntpq -p
Les informations peuvent éventuellement être également consultées via l’édition des fichiers du pseudo-système de fichiers /sys.







