

Le protocole IP
Sommaire
I. Définitions et généralités
Ce protocole permet de gérer l’acheminement des paquets d’une machine à une autre, ainsi que l’adressage. Au plus bas niveau (physique), on dispose alors d’interfaces pour communiquer d’un point à un autre. Grâce à trois champs du paquet, on peut facilement déterminer le destinataire d’un message :
- Le champ adresse IP
- Le champ masque sous-réseau
- Le champ passerelle
Les données circulent sur le réseau Internet sous forme de datagrammes (c’est pour cela que l’on parle alors de commutation de paquets). Les datagrammes sont des ensembles de données encapsulées, auxquelles on a ajouté des entêtes, correspondant aux informations liées à leur transport : adresse IP, destination, type de service…
La taille maximale d’un datagramme est de 65536 octets. Mais, cette valeur est rarement atteinte, car les réseaux ont une capacité moindre par rapport à une telle dimension. De plus, les réseaux utilisés pour propager de l’information sur Internet, sont adossés à différentes technologies, si bien que la taille maximale d’un datagramme peut également varier selon le type de réseau sous-jacent.
II. Fragmentation des datagrammes IP
La taille maximum d’une trame est appelée MTU (Maximum Transfer Unit) et entraine alors la fragmentation du datagramme, lorsque la taille de celui-ci est plus importante que le MTU du réseau considéré. Les MTU les plus fréquents sont :
- ARPANET : 1000
- ETHERNET : 1500
- FDDI : 4470
La fragmentation d’un datagramme s’effectue au niveau des équipements de routage, c’est-à-dire lors de la transition des datagrammes, d’un réseau dont le MTU est important à un réseau dont le MTU est plus réduit. Donc, lorsqu’un datagramme est trop grand pour passer en un seul morceau sur le réseau considéré, le routeur va le fragmenter (ou plus prosaïquement, le découper), en fragments de taille inférieure au MTU dudit réseau et de façon à ce que la taille du fragment soit un multiple de 8 octets :

L’équipement réseau peut ensuite envoyer ces fragments de façon autonome et les encapsuler (c’est-à-dire, ajouter un entête à chacun des fragments), pour tenir compte de la nouvelle taille du fragment (une sorte de ré étiquetage). Le routeur en profite également pour ajouter des informations à l’intention de la machine destinatrice afin qu’elle puisse réassembler les morceaux dans le bon ordre.
ATTENTION : à ce stade, on remarquera que rien n’indique que les fragments arriveront dans l’ordre souhaité au départ, étant donné que chacun d’eux est acheminé de façon indépendante.
III. Encapsulation des données
Afin de tenir compte des transformations et de la fragmentation, chaque datagramme se voit ajouté plusieurs champs, permettant de procéder au ré-assemblage ultérieur. Ce mécanisme, appelé l’encapsulation, permet de fournir les informations liées à chaque couche de passage du datagramme et de pouvoir faire en sorte d’acheminer correctement l’information vers son destinataire.
Ainsi, lors d’une transmission, les données traversent chaque couche du modèle TCP/IP de la machine émettrice et à chacune d’elles, une nouvelle information, appelée entête, est ajoutée au paquet de données. Il s’agit d’un ensemble de d’informations garantissant la transmission. Au niveau de la machine réceptrice, l’information transite alors par chacune des couches du modèle, l’entête est lue, puis supprimée. Ainsi, à la réception, le message se présente dans son état originel :
![]()
A chaque niveau, le paquet se transforme, puisqu’on lui ajoute de nouveaux entêtes dont les appellations changent au fil des couches :
- Le paquet de données est appelé message, au niveau de la couche Application.
- Le message après encapsulation, s’appelle un segment sur la couche Transport.
- Le segment une fois encapsulé s’apparente à un datagramme.
- Pour finir, au niveau Accès, on parle de trame.
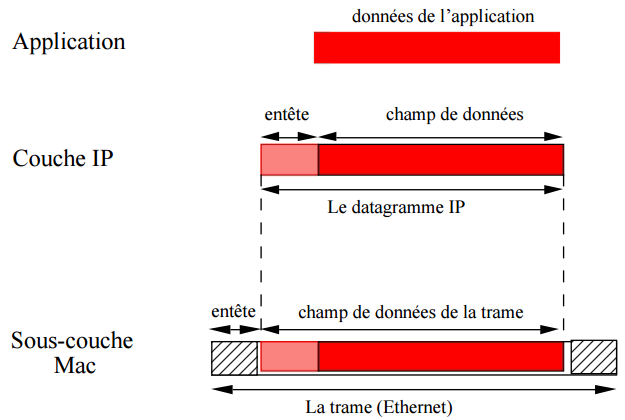
Au final, si l’on prend l’exemple d’une transmission d’un paquet depuis un client, à destination d’un serveur, on peut représenter le flux binaire et d’encapsulation de la façon suivante :
![]()
IV. Adressage IP
Mais, même en utilisant les différents principes décrits ci-dessus, le réseau nécessite de se repérer pour délivrer les paquets de données. Au niveau de la couche Internet, le protocole prévoit de fournir une identification unique pour chaque extrémité de la communication. C’est ce que l’on va appeler l’adresse IP (définie sur 32 bits), et constituée de quatre nombres, séparés par des points : N1.N2.N3.N4
En fait, cette adresse comporte elle-même deux parties :
- Une adresse réseau (aussi appelée netid)
- Une adresse hôte (au sein du réseau qu’elle adresse aussi appelée hostid)
Suivant les cas de figure, il existe quatre ou cinq classes d’adresses, notifiée par les lettres A à E :

IMPORTANT : il existe, comme on peut le constater, des catégories (ou des tranches) d’adresses qui ne peuvent en aucun cas être exploitées. En particulier, dans la classe C, il n’est possible d’avoir que 254 machines. Or, l’identifiant de la machine est codé sur 8 bits (soient 256 valeurs possibles). Les deux absents représentent respectivement :
- Pour la valeur 0 : l’adresse du réseau
- Pour la valeur 255 : l’adresse de diffusion (aussi appelée multidiffusion)
REMARQUE : en fonction de la classe d’adresse considérée, le nombre maximum de sous-réseaux (et donc, de machines ou d’adresses délivrées) varie :

De plus, au sein de chaque classe d’adresses, certaines ne peuvent être routées sur Internet et sont alors réservées aux réseaux locaux (ou aux réseaux privés). C’est d’ailleurs pour cela qu’on les appelle des adresses privées :
- Classe A : 10.0.0.0 à 10.255.255.255
- Classe B : 172.16.0.0 à 172.31.255.255
- Classe C : 192.168.0.0 à 192.168.255.255
-> Adresses devant être "natées" pour sortir sur Internet.
Exemple : soit l’adresse d’hôte 192.168.7.5, on peut déterminer les adresses suivantes :
- 192.168.7.0 : Adresse Réseau
- 192.168.7.1 : Adresse broadcast (ou diffusion)
- 192.168.7.5 : Adresse de machine (ou unicast)
- 224.x.x.x : Adresse multicast (aussi appelée Classe D multidiffusion)
Une adresse particulière : 127.0.0.1, représente l’adresse de loopback, aussi appelée bouclage et notée, (du moins sur des machine Linux), lo. Elle représente la machine elle-même (sans la nommer), ainsi que le sous-réseau identifié par 127.0.0.0/8.
En effet, chaque réseau peut être lui-même découpé en sous-réseaux, à l’aide de masques permettant un ciselage plus fin des adresses. Ainsi, le netmask (ou masque de sous-réseau), est un masque binaire permettant de séparer immédiatement, l’adresse réseau pour ce sous-réseau, de l’adresse de l’hôte, pour un message global. De la même façon que l’on a attribué des classes aux tranches d’adresses, on découpe les sous-réseaux en classes :
- Classe A : 255.0.0.0
- Classe B : 255.255.0.0
- Classe C : 255.255.255.0
La règle d’or, en matière de communication réseau, consiste à n’établir de lien qu’entre machines de même réseau ou de même sous-réseau. Ainsi, le calcul d’un sous-réseau s’effectue (en reprenant l’exemple ci-dessus), à partir des informations dont on dispose :
- Réseau : 192.168.1.0
- Adresse du Réseau : 192.168.1.255
- Masque de réseau : 255.255.255.0
Étape 1 : On doit alors déterminer combien de machines on souhaite intégrer dans le sous-réseau. En considérant qu’un réseau de classe C permet d’intégrer 254 machines (puisque 0 et 255 sont réservés). Si l’on se fixe, par exemple 60 machines à adresser (en ajoutant deux à cette valeur : une adresse pour le sous-réseau et une pour le broadcast), on obtient alors la valeur de 62.
Étape 2 : Une fois le nombre d’adresses déterminé, on doit trouver la puissance de 2 exacte (ou juste supérieure), au nombre fixé. D’après l’exemple, on aura 26=64.
Étape 3 : Il faut ensuite écrire le masque en binaire, en plaçant tous les bits du masque de réseau (ici de classe C), à 1 et en positionnant les n premiers bits du masque, correspondant à la partie machine, à 0 (d’après l’exemple n=6) :
![]()
Étape 4 : on peut alors convertir ce masque en décimal, soit 255.255.255.192 et calculer l’ensemble des sous-réseaux possible (en faisant varier les "y" derniers bits du masque correspondant alors à la partie machine soit, d’après l’exemple :
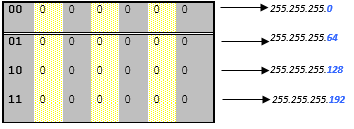
Étape 5 : au final, on obtient quatre sous-réseaux de 62 machines (soient un total de 248 machines), auxquelles on peut ajouter les 2x4 adresses réservées afin de disposer de 256 adresses potentielles.
Ce genre d’opération revient, en fait, à subdiviser le bloc "HostId", au sein de l’entête d’adresse en deux champs HostId et SubnetId :
![]()
V. Adressage CIDR
A l’orée des années 90, suite à l’engouement pour Internet, au niveau des entreprises, le système d’attribution des réseaux IP, basé sur le système des classes montra quelques limites, notamment en ce qui concerne les tables de routages. Il a donc fallu trouver une parade à ce problème. C’est ainsi qu’un nouveau système de répartition des adresses fut initialisé : le CIDR ou Classless Inter-Domain Routing (qui d’ailleurs à aujourd’hui supplanté le système des classes d’attribution d’adresses).
Le but était de pouvoir regrouper plusieurs réseaux de classes C en un seul bloc d’adresses de 2nx256 et n’avoir qu’une seule entrée en vis-à-vis de ces réseaux (avec agrégation de routes). On parlait alors de supernetting. Puis, ce mécanisme fut alors propagé aux réseaux de classe B (même si le besoin était moindre, par rapport à la classe C), puis aux réseaux de classe A (là, le besoin d’agrégation ne se pose même pas). En réalité, c’est l’ensemble de la représentation de l’espace d’adressage qui a été modifié.
Du coup, définir des masques réseau plus grands que celui de la classe naturelle du préfixe réseau, revient à exprimer un bloc CIDR. Ces blocs peuvent éventuellement, représenter des réseaux (au sens n° de réseau et de masque). Les blocs peuvent aussi être un ensemble de réseaux, de même préfixe, ou un seul et même réseau. Dans ce cas, la taille du bloc est égale au masque du réseau, ou à une portion de ce réseau.
Un bloc se définit par son préfixe séparé par le symbole "/" et suivi du nombre de bits représentatifs de la taille du bloc.
Exemple : /17 indique que les dix-sept premiers bits représentent la taille d’adresses ou le masque réseau. La taille du bloc est en fait de 2(32-n), où n représente la valeur mentionnée par /17 (soit 32-17=15, c’est-à-dire 215=131072 adresses IP. En déduisant les deux adresses particulières, on obtient 131070 adresses, au total).
Pour information voici, les quatre premières lignes du tableau de correspondance CIDR d’attribution des adresses :
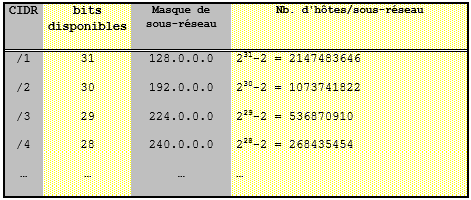
NOTE : le sous-réseau zéro était considéré comme un sous-réseau non standard, par le RFC 950, bien qu'utilisable. La pratique de réserver le sous-réseau 0 et le sous réseau 1 est cependant considéré comme obsolète, depuis le RFC 1878. Il s'agit du premier sous-réseau d'un réseau.
Exemple : le sous-réseau 1.0.0.0 avec 255.255.0.0 comme masque de sous-réseau.
Le problème, avec ce sous-réseau, c’est que l'adresse unicast pour le sous-réseau est la même que l'adresse unicast du réseau de classe A complet. Ce problème n'est plus d'actualité puisque cette réserve n'avait été conservée, que pour rester compatible avec de vieux matériels, ne sachant pas gérer le CIDR. Ce qui aujourd’hui n’est plus d’actualité.
ASTUCE : il existe bien évidemment un utilitaire permettant d’effectuer les calculs de masque de sous-réseau en notation CIDR, à la façon d’une calculette en intégrant les étapes mentionnées ci-dessus : il s’agit de l’outil ipcalc.








Bonjour, je suis confuse sur certains points.
Vous dites à l’étape 5 du calcul d’adresse des sous-réseaux qu’on peut ajouter 2×4 adresses reservées, mais quelles adresses réservées? parce qu’à l’étape 1 on dit qu’on voudrait 62 adresses déjà, (60 adresses machines, 1 adresse broadcast, et 1 @ du sous-réseau) pouvez-vous m’éclaircir sur ce point?
Autre point que je n’ai pas compris c’est la différence entre Réseau (192.168.1.0) et adresse réseau (192.168.1.255)?
(d’ailleurs dans l’exemple plus haut on a pris 192.168.7.0 comme adresse réseau, donc j’ai supposé que vous vouliez dire « Réseau (192.168.7.0) et adresse réseau (192.168.7.255) » je ne suis pas sûre d’avoir bien fait…
En tout cas merci bcp pour ce partage 🙂