Assignation des blocs d’adresses IPv6
Sommaire
I. Distribution des adresses
Comme on l’a mentionné plus haut, les adresses IP unicast sont distribuées par l’IANA aux registres Internet régionaux (aussi appelés RIR). Ceux-ci gèrent les ressources d’adressage IPv4 et IPv6, dans leur zone ou leur région.
L’IANA alloue alors des blocs de taille /23 à /12 (comme on l’a déjà dit ci-dessus), dans l’espace unicast global, aux cinq RIR déclarés. Ces derniers peuvent alors les allouer aux fournisseurs d’accès à Internet, sous forme de blocs minimum de /48.
REMARQUE : Les RIR peuvent alors décider de subdiviser leur bloc /23 en 512 blocs de /32 (soit un par fournisseur). Puis, ce dernier peut aussi assigner 65536 blocs /48 à ses clients, qui disposent à ce stade de 65536 réseaux /64.
On peut donc résumer cette répartition avec le tableau des structures de préfixes distribués, ci-dessous :

Étant donné le nombre et la disponibilité des adresses, l’utilisation du mécanisme NAT n’est plus vraiment de mise. Il est possible d’interroger les bases de données des RIR afin de connaître à qui (ou à quel organisme) est attribuée telle adresse IP, grâce à la commande whois (ou directement en ouvrant le site web du RIR).
De plus, afin d’encourager l’agrégation des adresses, le plan d’adressage IPv6 ne prévoyait au départ, que des blocs de type Provider Aggregatable (abrégés en PA), liés au fournisseur d’accès à Internet, lui-même. La possibilité d’être multi-hébergé (appelé multihoming) étant réalisé par l’assignation de plusieurs adresses de type PA aux équipements. Ce processus implique une renumérotation en cas de changement de FAI. Mais, le protocole IPv6 favorise ce mécanisme, grâce à la durée de vie et à l’auto configuration des adresses IP.
IMPORTANT : en 2009, la politique d’attribution des adresses IPv6 a été modifiée afin d’accepter l’assignation de blocs type Provider Independant (noté PI), aux entreprises désireuses de se connecter à plusieurs hébergeurs, la taille minimale du bloc assigné étant de /48. Le document RIPE 512 décrit la politique développée en la matière.
II. Notation des masques de sous-réseau
Un sous-réseau, au sens le plus large est un groupe d’adresses IPv6, commençant par une séquence binaire. Le nombre de bits inclus dans cette séquence est notée au format décimal derrière un caractère de barre oblique : ‘/’.
Exemple : cas du masque 2001:db8:1:1a0::/59
Il s’agit du sous-réseau correspondant aux adresses comprises entre 2001:db8:1:1a0:0:0:0:0 et 2001:db8:1:1bf:ffff:ffff:ffff:ffff
III. Paquets IPv6 et entêtes
Un paquet IPv6 possède également un entête fixe de 40 octets et il est possible qu’une ou plusieurs entêtes optionnelles d’extension, suivent immédiatement l’entête fixe IPv6. L’entête d’extension fournit des informations complémentaires.
Certaines entêtes ont un format fixe, mais, d’autres contiennent un nombre variable de champs également variables. Dans cette optique, chaque item est codé sous forme du triplet {Type, Longueur, Value}. Le champ Type fait un octet de longueur et précise la nature de l’option. Les différentes catégories ont été choisies de telle sorte à ce que les deux premiers bits précisent quoi faire, aux routeurs rencontrés, pour qu’ils sachent comment exécuter les instructions Leurs choix sont les suivants :
- Ignorer l’option
- Détruire le datagramme
- Retourner un message ICMP à la source
- Détruire le datagramme sans retourner de message ICMP (cas d’un paquet multidestinataire)
Le champ Longueur est également d’un octet et indique la taille du champ Valeur (de 0 à 255), contenant une information quelconque à l’intention du destinataire. Voici les différentes entêtes que l’on peut rencontrer.
On peut avoir affaire à une entête dite pas-à-pas (aussi appelée hop-by-hop), contenant des informations destinées aux routeurs rencontrés sur le parcours du datagramme. La structure générale de ce genre d’entête est la suivante :

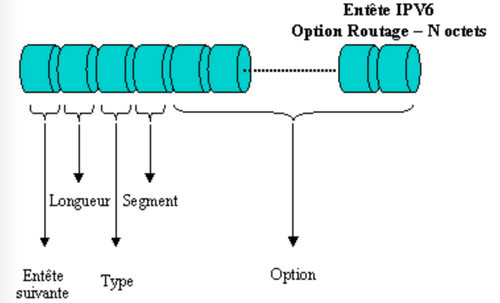
L’entête de routage fournit la liste d’un ou plusieurs routeurs devant être parcourus, sur le trajet vers la destination du paquet. On dénombre alors deux types de routage, souvent combinés ensemble : le routage strict (où la route intégrale est clairement établie) et le routage lâche (où seuls les routeurs obligatoires sont mentionnés).
Ainsi, les quatre premiers champs de l’entête routage contiennent quatre entiers d’un octet, chacun définissant respectivement :
- Le type d’entête suivant
- Le type de routage (généralement valorisé à 0)
- Le nombre d’adresses présentes dans l’entête (pouvant aller de 1 à 24)
- Une adresse fournissant la prochaine étape à visiter
REMARQUE : ce dernier champ débute avec la valeur zéro et est incrémenté lors de chaque étape ou chaque adresse visitée. La structure fournit par cette entête est la suivante :
Concernant la fragmentation, les champs relatifs à celle-ci ont été retirés de l’entête fixe, car IPv6 possède une approche quelque peu différente de celle d’IPv4. Tout d’abord, tous les ordinateurs et routeurs, conformes à IPv6 doivent supporter les datagrammes de 576 octets. Cette règle place la fragmentation dans une optique secondaire.
De plus, lorsqu’un hôte envoie un trop grand datagramme IPv6, contrairement à ce qu’il se passe avec la fragmentation IPv4, le routeur, qui ne peut transmettre le message, retourne alors un message d’erreur à la source. En effet, le message stipule à l’émetteur d’interrompre toute communication avec ce format vers la destination. Il est beaucoup plus efficace de transmettre l’information à la bonne dimension. Ainsi, les routeurs peuvent fragmenter les paquets à la volée.
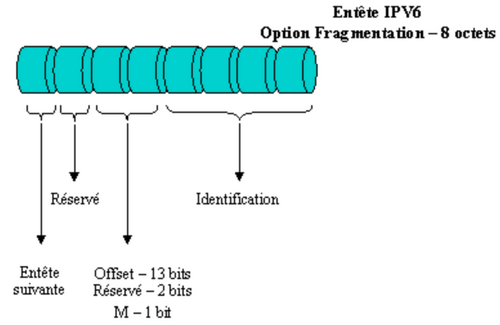
En effet, l’entête fragmentation traite celle-ci à l’identique de la méthode IPv4, car elle contient l’identifiant de datagramme, le numéro de fragment ainsi qu’un bit précisant si d’autres fragments suivent.
IMPORTANT : dans le protocole IPv6, seul l’ordinateur source peut fragmenter le datagramme. Les routeurs rencontrés sur le trajet ne le peuvent pas. Ainsi, l’hôte source peut fragmenter le datagramme en morceaux et utiliser l’entête fragmentation afin de transmettre les morceaux.
La structure de données proposées par l’entête fragmentation est la suivante :
L’entête authentification (aussi appelée AH ou Authentication Header), décrit un mécanisme permettant au destinataire d’un datagramme de valider l’identité de l’émetteur. On rappelle que dans le protocole IPv4, aucun mécanisme similaire n’est proposé. L’utilisation du chiffrement des données renforce alors la sécurité du datagramme, car seul le véritable destinataire peut lire les données.
Cette entête sert aussi au contrôle d’intégrité pour garantir au récepteur que personne n’a modifié le contenu du message, lors de son transfert sur le réseau. On peut éventuellement utiliser cette entête afin de détecter les "rejeux".
Son principe est très simple : l’émetteur calcule un authentificateur sur un datagramme et le diffuse avec le paquet sur lequel il porte. Le récepteur récupère cette valeur et s’assure qu’elle est authentique par rapport à son origine. Sa structure de données est la suivante :

L’entête Option de destination s’utilise pour des champs qui n’ont besoin d’être interprétés et compris que du seul hôte destinataire. Dans la version originale du protocole IPv6, la seule option de destination ayant été définie, est l’option nulle. Cela permet de compléter cette entête avec des zéros et obtenir alors un multiple de 8 octets.
REMARQUE : cette entête n’est pas utilisée pour le moment. Il a été défini pour s’assurer que les nouveaux logiciels de routage pourront l’utiliser, dans le cas où il serait envisagé une option de destination ultérieure. La structure de données associée est la suivante :