

Centralisation des logs : un atout clé pour la sécurité d’un SI
Sommaire
I. Présentation
Dans cet article, nous allons aborder le sujet des journaux d’évènement et leur centralisation. Il s’agit d’un élément central de la sécurité du système d’information, puisqu’une grande partie des activités de nos systèmes et applications se traduisent en journaux d’évènement.
Les journaux d’évènement sont un composant central de la vie et la sécurité du système d’information. Leur centralisation et surveillance font d’ailleurs partie des incontournables lorsque l’on se lance dans l’amélioration du niveau de sécurité et de robustesse d'un système d'information. Nous allons aujourd’hui voir en quoi consiste cette centralisation et quels sont ses intérêts et avantages en matière de gestion et de sécurité.
Version originale de l'article : 21 mars 2020.
II. Événement, log, journal et centralisation
A. Un log ou journal, qu’est-ce que c’est ?
Au sein d’un système d’information, chaque action ou opération génère un évènement, aussi appelé log : une trace écrite de l'activité du système. Il s’agit donc de la notification d'un événement d'une importance plus ou moins élevée enregistrée par un service, un système, un équipement réseau ou une application. Ces journaux d’événement sont horodatés et permettent tout simplement d’historiser et retracer les actions et la vie d'un système.
Ces journaux d'événements, souvent dispersés sur différents serveurs, applications ou équipements réseau, contiennent des informations précieuses pour assurer la sécurité et la bonne gestion du système d'information.
Note : dans la plupart des cas, les évènements sont regroupés au sein de fichiers ou dossiers que l’on nomme journal qui permettent de mieux organiser ces derniers par thématiques (sécurité, authentification, application, etc.).
Les journaux d’évènement permettent donc de savoir ce qu'il s'est passé à une date et une heure précise sur un équipement, un système ou une application pour :
- Expliquer une erreur, un comportement anormal ou un crash
- Retracer l’activité d'un utilisateur, d’une session, d'une application, d'un paquet sur un réseau, etc.
- Comprendre le fonctionnement d'une application, d'un protocole, d'un système comme les étapes de démarrage d'un service SSH sous Linux ;
- Être notifié d'un comportement, d'une action, d'une modification tel qu'une extinction ou un démarrage système ;
- etc.
Aujourd'hui, la grande majorité des systèmes, applications et éléments réseau produisent des logs. Dans la quasi-totalité des cas, ces logs sont stockés de manière locale sur la machine :
- Les journaux d’événements sous Windows sont stockés dans des fichiers comportant l’extension “.evtx” et sont visibles dans l’application Observateur d’événement.
- Sous Linux, c’est le fameux dossier "/var/log" qui contient une grande majorité des logs systèmes et applicatifs, ils sont ensuite gérés par le service “rsyslog”.
- Android stocke les logs des applications et du système dans le logcat.
- Chaque composant des plateformes clouds comme Azure produisent également leurs logs, qui sont disponibles à travers des interfaces dédiées.
- etc.
Pour mieux comprendre, voici un exemple d’évènement Windows visualisé dans l’Observateur d’évènements :

Cet évènement contient plusieurs informations, on y apprend qu’un mot de passe de compte utilisateur a été réinitialisé, que l’utilisateur (“Sujet”) qui a fait cette opération est “Administrateur” et que le compte ciblé par l’opération est “LINDA_PIERCE”. Cet événement, comme l’opération qui l'a généré, ont eu lieu sur le serveur “AD01.it-connect.tech”. Cela signifie qu’il faut aller se connecter sur le serveur, puis ouvrir l’Observateur d’évènement pour le visualiser.
Seulement, comment détecter une attaque qui consisterait pour l’attaquant à tenter de s’authentifier avec un compte sur l’AD01, un autre compte sur l’AD02, puis un troisième sur l’AD03 ? Il faudrait se connecter sur chacun, comparer les heures de connexion, la source, etc. Cela parait bien fastidieux et chronophage pour une opération qui, côté attaquant, peut être réalisée en quelques secondes.
B. Centralisation des logs : de quoi parle-t-on ?
Dans ce contexte, la centralisation des logs consiste à dupliquer l'ensemble des journaux des systèmes, applications et services de notre système d’information et d’en envoyer une copie sur un système ou une plateforme dédiée.
Ainsi, plutôt que d’être uniquement stockés sur chaque système, tous les journaux de ces systèmes seront stockés et aussi accessibles en un même endroit :

La centralisation de l'information permettra ici de mener plusieurs opérations qui iront toutes dans le sens de la sécurité et de la meilleure gestion du système d'information. C’est ce que nous allons voir dans la suite de cet article.
III. À quoi sert la centralisation, pourquoi centraliser les logs ?
Nous allons à présent voir à quels besoins répond concrètement la centralisation des journaux d’évènement au sein d’un système d’information.
A. Un outil de sécurité et d’alerte
La multiplicité des systèmes, des formats de logs et des types d’évènements générés rendent très complexe, voire impossible, la gestion de la cybersécurité au sein d’un système d’information sans centralisation des journaux d’évènements.
Lors d’une intrusion, un attaquant peut tenter d’exploiter une vulnérabilité sur un système A, déposer un ransowmare sur un système B, puis compromettre un compte administrateur sur l’Active Directory en quelques minutes. Il apparait donc très compliqué d’aller manuellement sur chacun des équipements du système d’information pour étudier ce qu’il s’est passé, faire de la corrélation entre les évènements, et en déduire qu’une attaque est en cours.
La corrélation en cybersécurité consiste à analyser et relier des événements provenant de différentes sources pour identifier des patterns ou des activités suspectes. Par exemple, elle permet de connecter une tentative de connexion échouée sur un serveur à une élévation de privilèges sur un poste utilisateur. Cela offre une vue d'ensemble des incidents et aide à détecter des menaces complexes qui ne seraient pas visibles en analysant chaque log individuellement.
En centralisant les journaux d’évènement sur un même système, nous pourrons avoir une vue globale et unifiée des évènements de différents systèmes. Nous pourrons alors à la fois visualiser les évènements de l’Active Directory, mais aussi de tous les postes utilisateurs et serveurs. Voyons à présent les contextes concrets dans lesquels cela pourra nous être utile.
- Avoir une vue d’ensemble et faire des statistiques
La centralisation des évènements, couplée à l’utilisation des applications de traitement, indexation et recherche permet d'avoir une vue en temps réelle de tous les évènements de sécurité des composants du système d’information et de les visualiser grâces à des graphiques, d’y appliquer des filtres, etc.
Il devient alors facile de savoir combien de tentative d’authentification ont été réalisés sur une période donnée, de détecter des comportements anormaux, comme un volume inhabituel de connexions échouées provenant d'une adresse IP spécifique, ou encore d’identifier des activités suspectes, telles que des transferts de données en dehors des horaires de travail.
- Permettre la mise en place de services de détection et de corrélation
La possibilité de traiter en un seul et même endroit les journaux de différents systèmes permet d’alimenter des outils de sécurité tels que des IDS (Intrusion Detection System) ou des SIEM (Security Information and Event Management). Ces derniers deviennent de véritables tours de contrôle de la cybersécurité au sein du système d’information et offrent une vision centralisée et exhaustive des événements de sécurité.
Les IDS et SIEM sont aujourd’hui des outils incontournables pour la sécurisation et la surveillance d’un système d’information, Voici en exemple la vue d’une console du SIEM ELK (ElasticSearch, LogsStach, Kibana) qui permet ici de visualiser l’apparition de certains évènements dans le temps, mais aussi de faire apparaitre leurs détails comme le système concernés (source de l’évènement) :

Cet outil permet donc de faire des recherches sur les journaux de plusieurs systèmes au sein d’une interface unique, en utilisant par exemple des filtres sur certains EventID, une plage horaire, un nom d’utilisateur ou encore de poste bien précis. Le tout sans avoir à se connecter à plusieurs systèmes.
On peut également mentionner les XDR (Extended Detection & Response), une évolution des SIEM, qui étend cette corrélation d’événements en intégrant des sources de données encore plus diversifiées (réseaux, endpoints, emails, etc.). Les XDR apportent une intelligence supplémentaire qui permet de détecter et catégoriser des attaques complexes sur plusieurs vecteurs, tout en proposant des réponses automatisées et proactives, telles que le blocage d’une adresse IP malveillante ou l’isolement d’un appareil compromis. Wazuh est par exemple un XDR connu et open-source, il permet, entre autres, d’associer un ensemble d’évènements à un TTP du MITRE ATT&CK pour faciliter le travail des analystes :
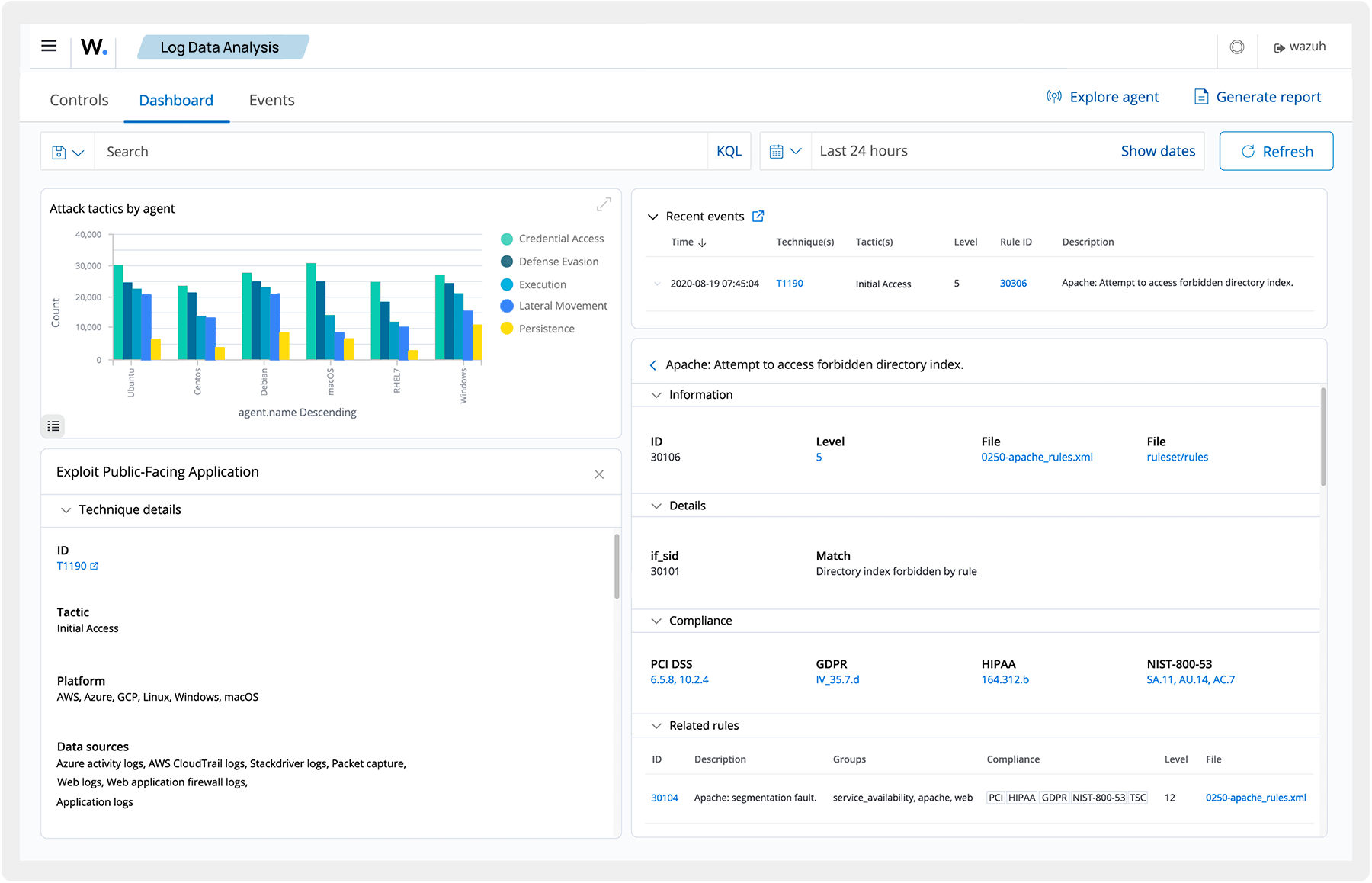
Les SIEM et XDR s’intègrent ensuite dans des SOC (Security Operation Centers), qui unifient technologies, personnel et procédures organisationnelles pour détecter, répondre et gérer efficacement les incidents de sécurité dans une entreprise.

Toutes ces technologies et plateformes, qui visent à améliorer la visibilité sur les menaces, gérer les processus de détection et de réponse, ont pour même base de travail les journaux et au préalable, leur centralisation. La conclusion logique des bénéfices de la centralisation des journaux d’évènements et de ces différents outils est la réduction du temps de détection et de réponses face aux incidents de sécurité.
- Faciliter la recherche de menace et les investigations numériques
Les investigations numériques (forensic) et la recherche de menace (démarche proactive de recherche de traces de compromission) sont grandement facilités par la centralisation des logs. Encore une fois, car il est plus rapide de faire ses recherches dans un seul et même endroit plutôt que de se connecter individuellement à tous les systèmes du SI.
En centralisant nos journaux au sein d’un même système, il devient possible de retracer précisément le parcours d’un attaquant sur plusieurs équipements au sein du système d’information.
Si vous souhaitez voir en conditions réelles l’utilisation des journaux d’évènements pour l’investigation numérique au sein d’un SIEM, je vous invite à consulter nos articles Hack The Box Sherlocks qui portent précisément sur ce sujet :
- IT-Connect.fr - Investiguer sur une attaque ASREPRoast via ELK – Hack The Box Sherlocks : Campfire-2
- IT-Connect.fr - Investiguer sur une attaque Kerberoasting via ELK – Hack The Box Sherlocks : Campfire-1
B. Un outil d’archivage et de diagnostic
Au-delà de faciliter la détection et la recherche d’incidents de cybersécurité, qui est souvent la principale raison de sa mise en place, la centralisation des journaux d’évènements peut aussi avoir plusieurs intérêts techniques, voire légaux :
- Diagnostiquer un crash
Il peut être très utile de savoir exactement ce qu'il s'est passé lorsqu'un système devient complètement injoignable (après un crash sévère par exemple). Si les logs qui permettent de diagnostiquer la panne se trouvent sur ladite machine, ils sont difficilement atteignables (on peut toujours extraire les disques, les lires sur un autre périphérique, etc.). Dans le cas où les logs sont exportés sur une machine dont la disponibilité est assurée, il est alors possible de rapidement récupérer les derniers événements systèmes de la machine endommagée pour diagnostiquer plus facilement.
- Garantir la survie des logs à une suppression
Il est très fréquent lors d’une intrusion que l’attaquant cherche à effacer ses traces sur les systèmes compromis. Cela pour rendre plus complexe l’analyse de ses actions par des équipes de sécurité ainsi que la découverte d’éventuelles portes dérobées qu’il aurait pu laisser au sein du système d’information.
Vous trouverez plus d’information sur cette opération malveillante, très connue et documentée, dans le TTP associé du framework MITRE ATT&CK :
- MITRE ATT&CK - T1070 : Indicator Removal
Cette opération, passe alors en partie par la suppression des logs et historiques qui peuvent donner des indications sur les actions menées pendant l'intrusion, et donc aider à identifier l’attaquant et ses objectifs. Lorsque les logs sont stockés en local, ceux qui sont supprimés sont alors difficilement récupérables. S‘ils ont été envoyés sur un système distant dont le rôle est de les centraliser (et archiver), il devient possible de récupérer des informations très importantes à propos des actions menées.
Notons que la suppression ou perte des logs peut également arriver dans d'autres contextes plus proches de la vie quotidienne d'un SI, telle que la perte d'un disque, d'une partition dédiée aux logs, la mauvaise manipulation d'un administrateur système pressé ou même la rotation classique des journaux d’évènements pour éviter la saturation de l’espace disque.
- Obligation légale
Bien que la centralisation des logs ne soit pas explicitement imposée par une réglementation spécifique, plusieurs réglementations mentionnent ou impliquent indirectement cette pratique dans le cadre de la sécurité des systèmes d'information et de la protection des données.
On peut notamment citer le RGPD, qui ne mentionne pas directement la centralisation des logs, mais impose des exigences qui peuvent y faire appel comme la traçabilité des accès aux données personnelles ou la détection et notification des violations de donnée.
Peut également être mentionnée la norme PCI DSS (Payment Card Industry Data Security Standard), qui exige la collecte et l'analyse des logs pour les systèmes traitant des données de cartes de paiement (Source PCI DSS Logging and Monitoring Requirements).
La centralisation et l’analyse des logs sont donc également des outils de conformité réglementaire, précisément grâce aux différents bénéfices que nous venons d’évoquer (archivage, collecte unifiée, facilitation des détections, etc.).
IV. Comment fonctionne la centralisation des logs ?
La centralisation des journaux d’évènements n'est pas un processus qui se fait du jour au lendemain, sauf si vous avez la chance et la bonne idée d'y penser dès les premiers pas de votre SI. Son déploiement se fait en plusieurs étapes, que nous allons rapidement parcourir
A. Bien gérer la production des journaux d’évènements
La première chose à faire est bien entendu de configurer les équipements, applications et système afin qu’ils produisent les journaux d’évènements souhaités. Cela nécessite, d’une part, de connaitre les capacités de journalisation de ces différents composants, et d’autre part, de les configurer efficacement pour que les évènements qui ont un intérêt du point de vue sécurité soient bien générés.
Note : En fonction des capacités de chaque système, de la verbosité de la journalisation ainsi que de l’activité quotidienne à surveiller, les journaux d’évènements peuvent prendre une certaine place ! Il s’agit donc également d’anticiper le volume de données à stocker et de calibrer les ressources systèmes en conséquence pour éviter une saturation.
Il faut donc veiller à correctement définir ce que l'on souhaite voir, ce que l'on souhaite garder en local et ce que l'on souhaite envoyer sur un serveur de logs distant. Cela demande un certain travail et une vision globale du système d'information, car il est nécessaire d'effectuer cette tâche sur tous les systèmes et les applications à surveiller, tout dépendra donc de la taille de votre système d'information.
À ce titre, il existe à présent de très bonnes ressources pour configurer ces journaux d’évènements afin d’avoir accès aux évènements de sécurité à surveiller. On peut notamment citer le guide de l’ANSSI “Recommandations de sécurité pour la journalisation des systèmes Microsoft Windows en environnement Active Directory”, qui décrit à la fois les grandes phrases de mise en œuvre de la journalisation des systèmes Windows, mais aussi la configuration précise à mettre en place pour ne passer à côté d’aucun évènement de sécurité important :

Cet extrait montre par exemple une partie des recommandations de l’ANSSI concernant la configuration des évènements relatifs à Kerberos sur une Active Directory. Vous pourrez retrouver ce guide ainsi que de nombreux autres sur le site officiel de l’ANSSI :
Vous trouverez également de nombreux guides de bonnes pratiques sur le site du CIS (Center for Internet Security) ou encore sur les sites officiels des systèmes, équipements et applications que vous souhaitez surveiller.
B. Stockage et envoi des logs sur une plateforme dédiée
Une fois que nos évènements de sécurité sont bien générés et stockés en local sur chacun des systèmes, nous pouvons passer à la phase de centralisation.
Il est dans un premier temps nécessaire de réfléchir à l’architecture à mettre en place. Notamment en isolant au maximum les serveurs de collecte et de traitement des journaux centralisés afin qu’ils ne deviennent pas des cibles pour les attaquants souhaitent en apprendre plus sur notre réseau ou effacer leurs traces. Il faut donc penser au positionnement de ces serveurs, mais aussi à leur cloisonnement vis-à-vis du reste du réseau.
Concernant le serveur de collecte et traitement des journaux, plusieurs technologies peuvent ici être utilisées, du simple collecteur de journaux d’évènements au SIEM jusqu’à l’XDR, nous pouvons par exemple mentionner :
- Graylog : solution open-source de gestion des journaux permettant de collecter, analyser et visualiser les événements en temps réel via une interface web.
- ELK : Elasticsearch, Logstash, Kibana, est un ensemble puissant et flexible d’outils qui centralise les logs, les analyse et les affiche sous forme de tableaux de bord personnalisables, mais permet aussi des recherches interactives.
- Splunk : plateforme propriétaire pour la gestion et l’analyse des données, incluant des fonctionnalités avancées de corrélation et d’alertes
- Wazuh : solution gratuite et open-source qui combine collecte de logs et fonctionnalités EDR pour une surveillance plus avancée de la sécurité des systèmes
L’envoi des journaux d’évènements peut être réalisée soit grâce aux capacités natives des applications, équipements réseau ou système dont les fonctionnalités par défaut permettent d’envoyer les journaux générés en local et sur un serveur distant, soit grâce à des agents tiers propres aux solutions utilisées. Pour mieux comprendre, vous pouvez jeter un œil à nos différents tutoriels à ce sujet :
- IT-Connect.fr - Linux : envoyer les logs vers Graylog avec rsyslog
- IT-Connect.fr - Envoyer les logs Windows vers Graylog avec NXLog
- IT-Connect.fr - Cisco : Envoi des logs sur un serveur distant
Cependant, il faut toujours être vigilant sur la confidentialité des échanges entre le serveur de collecte des journaux et ses clients. Notamment concernant leur chiffrement ainsi que leur parcours sur le réseau. Il peut également être nécessaire de mettre en place des serveurs de collecte intermédiaires qui permettront de faire le pont entre le serveur de collecte, isolé du réseau, et des réseaux plus exposés aux cyberattaques comme la DMZ ou la zone utilisateurs, sans parler des situations de nomadismes ou des sites géographiques distants.
C. Indexation, analyse et utilisation des données
Une fois que les journaux d’évènements de chaque système, équipement et application sont réunis au sein d’une plateforme unique et dédiée, ceux-ci sont généralement indexés et formatés de manière à pouvoir être requêtés de manière unifiée.
Cette opération permet de s’assurer que leur traitement puisse être réalisé facilement et rapidement afin d’atteindre les objectifs de surveillance, d’alerte et de sécurité mentionnés précédemment. C’est là qu’interviennent les principales capacités des solutions de types SIEM et XDR que nous avons mentionnées, qui possèdent souvent leur propre langage de requête, technique d’indexation et représentation des données.
À titre d’exemple, la requête suivante provient du langage KQL du SIEM ELK et permet de retrouver toutes les tentatives d’authentification réalisées par les utilisateurs du SI auprès de l’Active Directory :
event.provider: Microsoft-Windows-Security-Auditing and (event.code:4776 or event.code: 4771)Voici un résultat possible d’une telle requête :

C’est au sein de ces plateformes que les équipes de sécurité vont pouvoir visualiser les évènements en temps réel, rechercher et filtrer dans tous les évènements de sécurité présents ou passés et ainsi détecter des traces d’attaque que sein du système d’information.
V. Conclusion
Nous sommes loin d’avoir fait le tour des outils et éléments à connaitre au sujet de la centralisation des logs, il s’agit d’un long processus qui nécessite une planification et un suivi régulier.
La centralisation des logs est relativement simple à mettre en place au sein de systèmes d'information peu étendus (au niveau réseau comme au niveau géographique), cela s'avère plus complexe sur des SI de grande taille, mais c'est une opération à mener à tout prix pour éviter certains risques et avoir une vue réelle de l'état d'un système d'information.
N’hésitez pas à partager dans les commentaires vos retours d’expérience, outils et astuces à ce sujet afin qu’ils profitent à tous !











Merci pour cette article. C’est un sujet auquel je m’intéresse et que je vais lire avec attention.
merci énormément pour c sujet , j’ai bcp appris vraiment merci… si possible mm de créer aussi un truc du genre l forum
Bonsoir, sujet très vaste et vital pour avoir une visibilité sur son infrastructure.
Comment faire pour utiliser des outils Open Source dans devoir réinventer la roue…
ELK est une usine gaz et c’est casse bonbon à maintenir.
Je conseille plutôt : Loki, promtail et Grafana.
Tout dépend des besoins, si le besoin c’est juste un « grep » oui en effet.
Merci beaucoup pour cet article, c’est au programme du BTS SIO, une partie qui n’est pas simple à aborder, mais que j’appréhende mieux maintenant 🙂
Article très pertinent. Merci à vous pour votre clarté